
Sasha Rezvina

When your team is building a software product, the majority of the work that they do is invisible. As a manager, you have to rely on in-person cues for blocked work or frustrated engineers. When they move to a remote workflow—your team also becomes invisible, and all those critical signals are dropped.
In-person, you might notice:
- Nonverbal clues during stand-ups or retros
- Frequent interruptions as developers are pulled into meeting after meeting
- Tension between team members as they work through problems
Acting on these signals is one of the most important ways you can help your team. You might say: “I noticed you seem frustrated each time you worked with Jack—is everything okay?” Or “I noticed that you’ve been helping the marketing team a lot, do you have too much on your plate right now?”
When you transition to a remote workflow, you lose indicators that anyone is stuck, demotivated, or overworked. To adjust, you have to find new ways to broaden the now-limited purview that remote work allows.
Signals to Remain Context-Aware From Afar
When thinking about productivity or output, many software leaders think in terms of features or story points. They get a general sense of how things are moving (or not moving) based on whether these features are getting completed. But these metrics are lagging indicators, and they’re not diagnostic. If you know that you’ve shipped fewer features one sprint than you did in the previous, you have no insight into what you can do to improve things.
Fortunately, we can derive much more granular signals for the speed and effectiveness of software development from the systems in which engineers already work. Data from how a developer works in their version control system, such as Commit Volume, Code Churn, or Pull Request Cycle Time, better clues you into how your team is working in real-time.
These metrics are imperfect (as all metrics are), but they give you much more to work with in terms of diagnosing process problems within your newly-distributed workflow. Below, we’ve recommended a set of metrics that you can look at on a daily, weekly, and monthly basis to stay connected with how your team is working.
Daily Signals for Stuck Work
The most imminent threat to an efficient and happy remote team is stuck work.
An engineer might be stuck because they are unsure of how to implement a change, because they’re unfamiliar with a portion of the codebase or for a number of other reasons. Any unit of work that isn’t moving through the Software Delivery Process quickly enough is a signal for you to check in. Look out for:
- Infrequent pushes: Are team members working incrementally? Are they working on a particularly tough portion of the codebase?
- Rework: Are team members reworking the same lines of code over and over again? Is there clear communication surrounding feature implementation?
- Long-running Pull Requests: Are there Pull Requests that have been open for more than three business days? Is this causing multi-tasking?
- Pull Requests with 3+ participants: Is a single Pull Request taking up the attention of several engineers who may be in disagreement?
- Pull Requests stuck in code review: Are there Pull Requests that have been passed back and forth between the reviewer and the author several times?
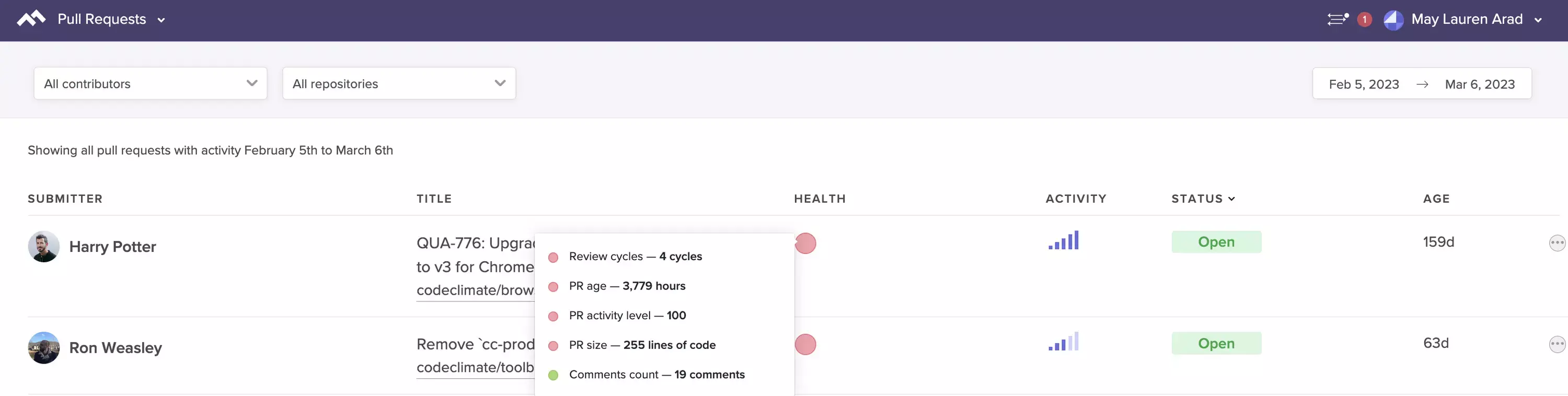
See at-a-glance the Pull Requests that are most likely to impede your team.
If you look at these signals with your team, you’ll have a shared understanding of how things are moving and where someone might be stuck. This data will take the pressure off developers to raise their hand during daily stand-ups when something’s off track, and enable you, as a manager, to know when you can step in and help.
Weekly Signals for Goal Setting
Once you’ve started tracking daily signals to keep your team on track, you can take a step back and start looking at how your engineers are working. If individual engineers are spending days working through a problem on their individual device, then opening huge Pull Requests that are perpetually getting stuck in the review process, your team will constantly feel stuck and frustrated.
Agile and Continuous Delivery workflows demand that team members commit frequently, work in small batches, and limit work in progress. These habits set in motion what we call the Virtuous Circle of Software Delivery:
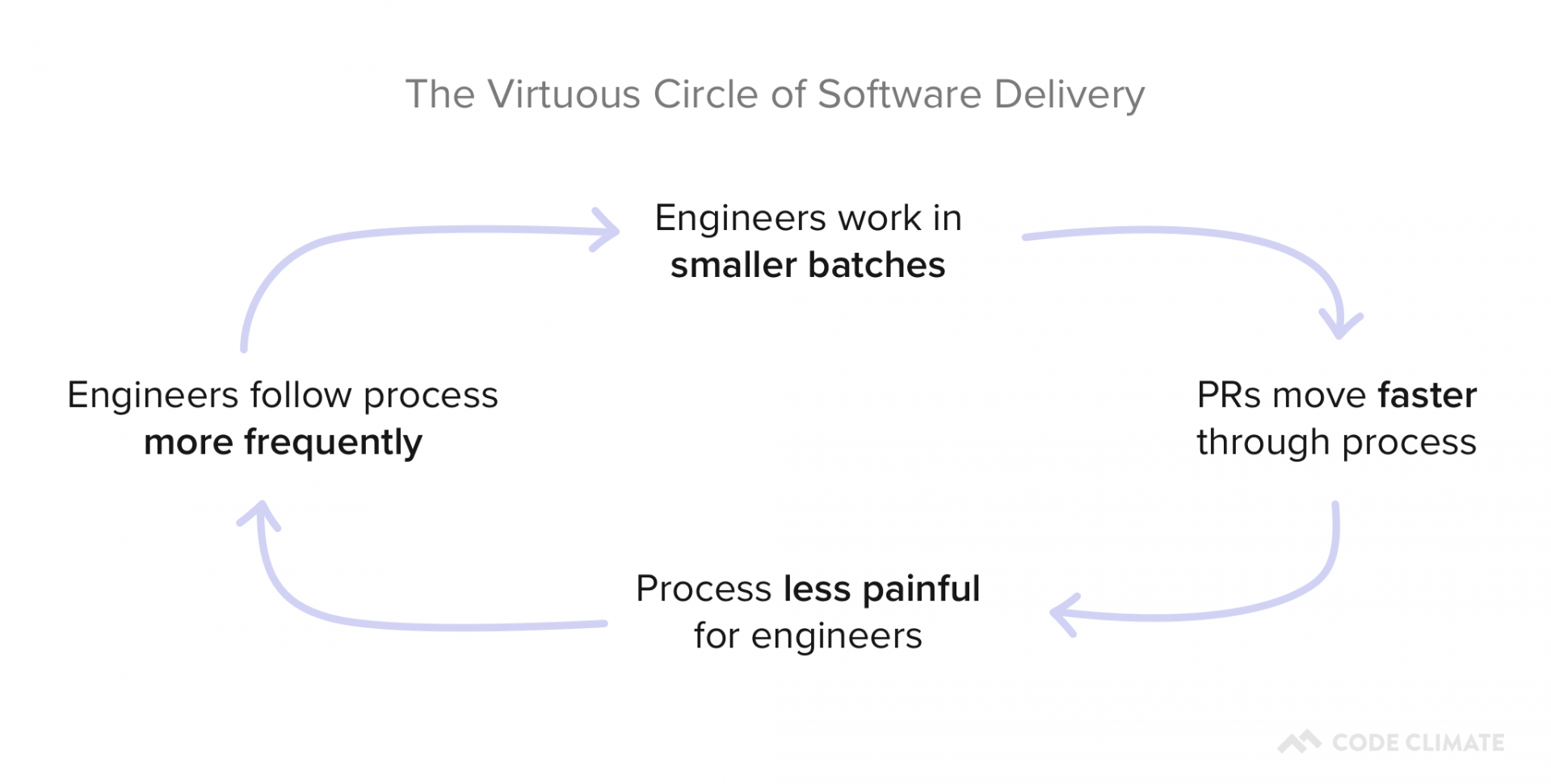
Building these habits is crucial to minimize the risk associated with merging a PR and decrease the chances that an individual unit of work will get stuck in the process.
For this, we recommend working with team members to set up process SLAs for good collaborative practices every week. Then, during retros and 1:1s, developers can work through concrete examples of when something went off track.
You can set targets for things like:
- Pull Request Success Rate: Can we agree that 95% of PRs should be successfully merged? We’ll investigate PRs that were closed or abandoned.
- Pull Request Time to Review: Can we agree to get to code reviews within 8 hours for 80% of Pull Requests? We’ll look deeper into PRs that couldn’t be reviewed quickly.
- Pull Requests Review Cycles: Can we agree to keep Review Cycles under 2 for 95% of Pull Requests? We’ll look into any PRs that get passed back and forth between author and reviewer multiple times.
- Workload Balance: Can we agree that 70% of the work should be done by at least 50% of the team? We’ll investigate deeper if just a few individuals seem to be doing most of the work.
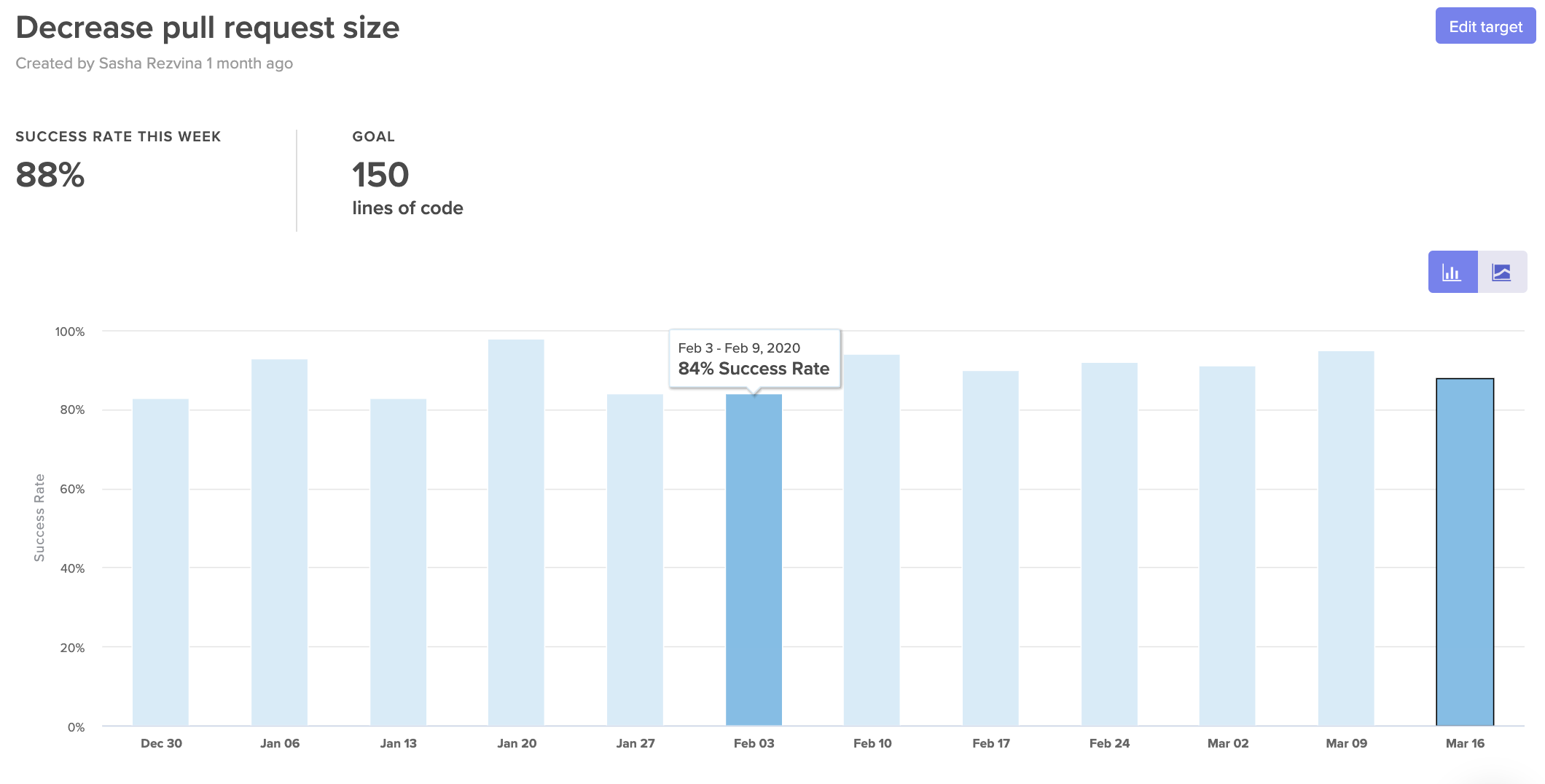
Set SLAs to help hold your team accountable to their goals.
Naturally, you don’t need to look at all of these metrics right away—just pick one or two that represent commonly reported issues. Selecting a granular metric, like Workload Balance, will be a much more effective indicator of what’s going amiss than a metric like Features Completed.
Over time, your team can build habits that minimize the opportunity for work to get stuck and slow down the team.
Monthly Signals for Continuous Improvement
Once you’ve identified signals that can point you towards daily and weekly improvement opportunities, you’ll want to start looking at your processes end-to-end to ensure that they’re working for, not against, your team members.
First, you’ll want to make sure your processes work. If you’re working in a traditional Git workflow, you’ll want to make sure that PRs are moving along the “happy path” from Open to Reviewed to Approved to Merged. Any PRs that skip steps are working outside your process and represent opportunities for deeper investigation.
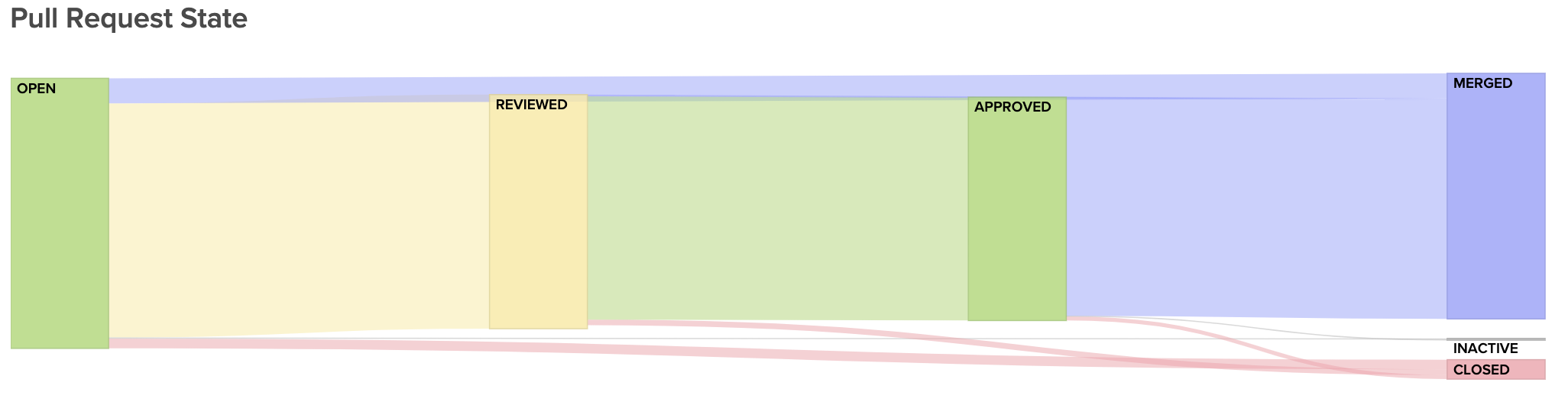
Visualize the journey of your Pull Requests from open to merged. Below, you can see metrics that represent constituents of this journey to better diagnose slowdowns.
Next, you’ll want to see how well this process is enabling a low time-to-market. If it takes days or weeks for changes to get into the hands of customers, your team will have a hard time quickly mitigating issues in production, and, ultimately, keeping up innovation.
For this, you’ll want to keep an eye on your team’s delivery Cycle Time, or how long, on average, it takes PRs to go from a developer’s laptop to being merged to production.
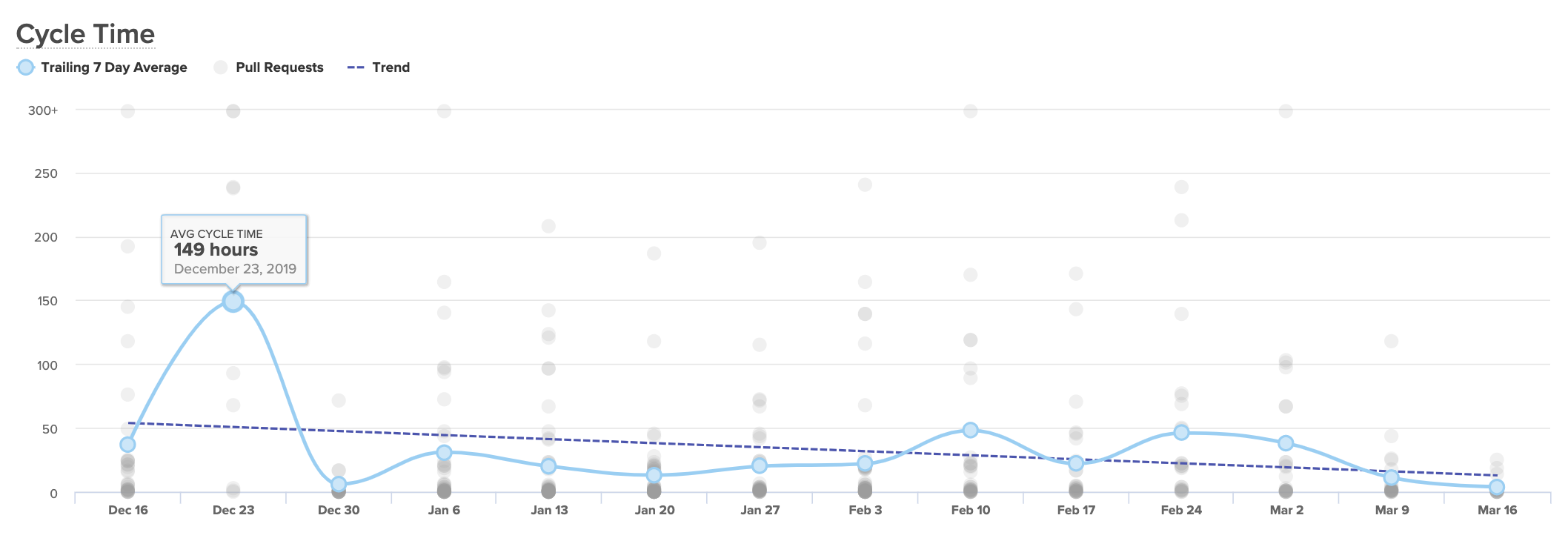
A Cycle Time that’s short and consistent is an indicator that your team is working with little friction, and your processes are enabling rapid innovation. If your Cycle Time is spikey, you’ll know to look into the units of work that make up a particularly high week.
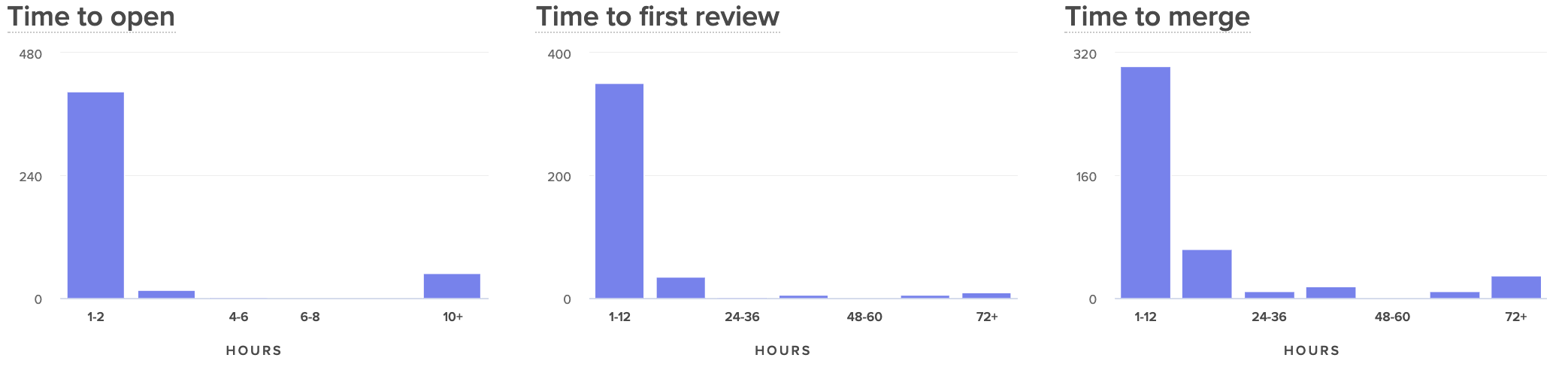
If your Cycle Time seems consistently high, you’ll want to break it up into components to see, specifically, which processes or practices are dragging down your speed. We recommend looking at:
- Time to Open: How much time passes between the earliest commit and the opening of a Pull Request?
- Time to First Review: How much time passes between when a PR is opened and when it is first reviewed?
- Time to Merge: How much time passes between when a PR is opened and when it is merged to production?
Comparing these side by side will help you see where in your process your developers are being slowed down.
When your team moves the needle and improves Cycle Time, it means you’re working together to boost the efficiency of the development process and to accelerate innovation. It’s important to communicate and celebrate success surrounding this metric to encourage continuous improvement on your team.
Remote Engineers Deserve Great Leaders
An unexpected transition to remote work is one of the most trying experiences for many software engineers. The already-isolating job of writing code becomes even harder when team members can’t chat or take breaks together. Leadership that is disconnected or not aware of all the challenges that they’re facing can be the final nudge that can disengage a team member.
Fold in just a few extra signals to stay aligned with engineers and lend a hand when they need it most.
Request a consultation to learn more.Request a consultation to learn more.

“Our analysis is clear: in today’s fast-moving and competitive world, the best thing you can do for your products, your company, and your people is institute a culture of experimentation and learning, and invest in the technical and management capabilities that enable it.” – Nicole Forsgren, Jez Humble, and Gene Kim, Accelerate.
After finishing the Accelerate book, many engineering leaders are determined to build a high-performance team. Readers go to the ends of the internet looking for the right tools and processes to facilitate speed and stability.
Lucky for us, to summarize every area that can be improved and move the needle, the authors put together this simple flowchart:
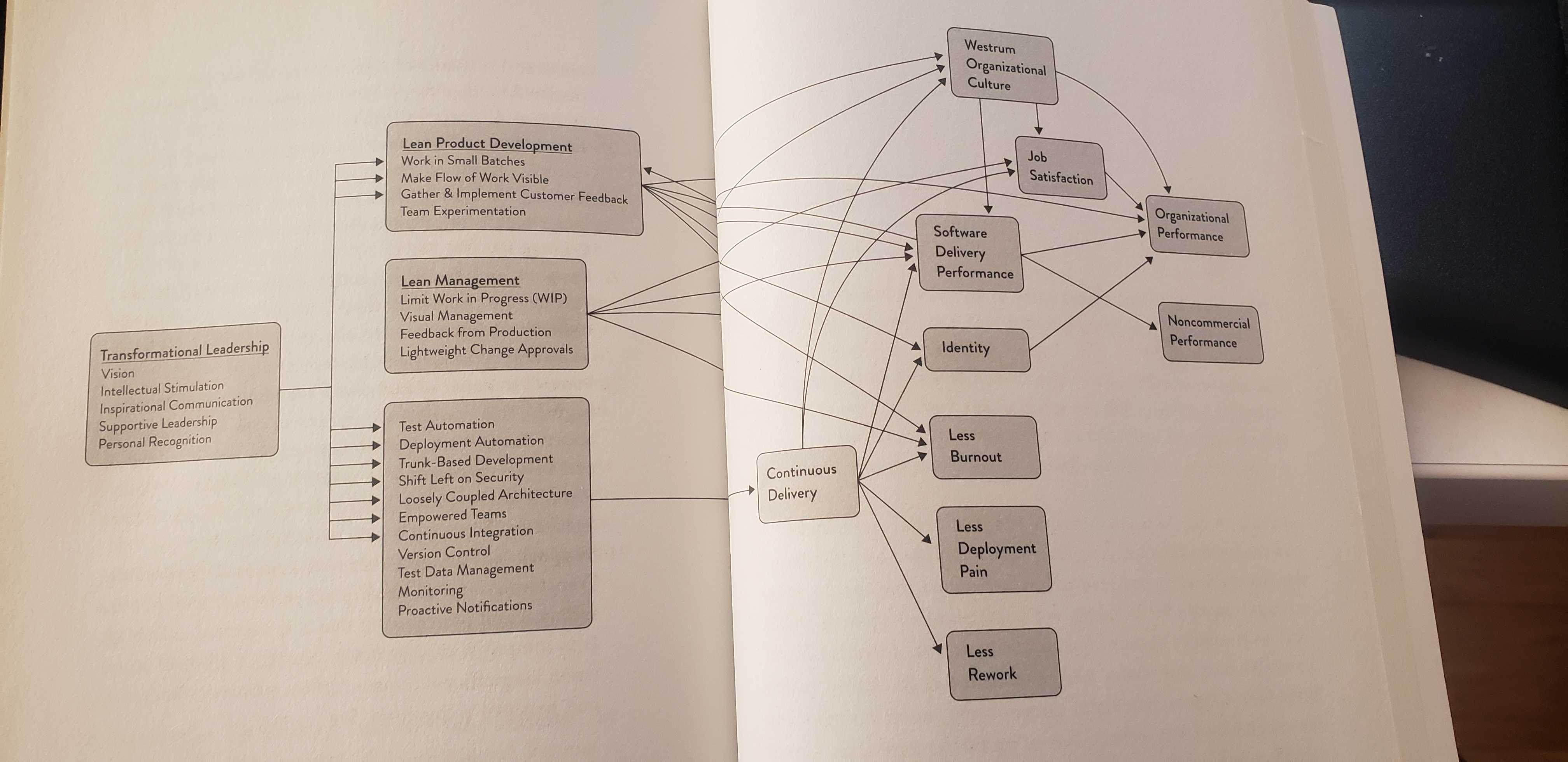
Just kidding. It’s not simple at all.
The tl;dr of the chart above is that changes to behaviors, processes, and culture influence several outcomes, such as burnout, deployment pain, or overall organizational performance. So while the book gives you a comprehensive explanation of everything that can be done, it doesn’t answer the most important question: if I want to improve how my team works, where do I start?
Metrics != Strategy
Ever since we built a Software Engineering Intelligence (SEI) platform, many engineering leaders have come to us and asked: “What metrics should I track?” And more recently: “How do I track Accelerate metrics within the platform?”
The Accelerate metrics, specifically, are valuable in giving engineering executives an understanding of where their organization stands, compared to the rest of the industry. They’re not:
- Specific to the problem you’re trying to solve.
- Diagnostic to indicate when you should take action.
While engineering teams can track Accelerate metrics in their custom-designed SEI platform, powered by Code Climate (along with 40+ other metrics), we always advise leaders to first take a step back and consider what they’re trying to improve. Quantitative measures are a powerful tool to measure progress toward objectives—but these objectives can vary drastically between organizations or even between teams. Measuring metrics with no end goal in mind can lead to poor decision-making and a focus on the wrong priorities.
Instead, we recommend starting by determining your team’s objectives and then pairing them with the appropriate metrics. Then you can use metrics as a means to an end: measuring progress toward a clear direction. This will ensure your metrics are more actionable in the short term and will be received more favorably by the team.
Specific: Start with the Pain
We always recommend that engineering leaders begin with qualitative research. Prioritize conversations before looking at quantitative measures to work through the most immediate and painful issues.
Through stand-ups, retrospectives, and 1:1s, work to understand what feels broken to the engineers. To avoid exposure or recency bias, collaborate with peers in management or lead engineers to gather this data to find repeat points of friction.
Based on your team’s observations, record your hypothesis:
Our code review process is often painful. I’ve heard that some reviewers “always approve PRs,” and often overlook defects. Other team members complain that specific individuals consistently ask for multiple rounds of changes, regardless of the magnitude of the change.
Try to include concrete details to make sure you’ve completely and accurately captured your team’s shared sentiment. Once you’ve worked to understand the day-to-day friction, only then should you begin to look at quantitative measures. The example above might call for the following metrics:
- Code Review Speed: How quickly do reviewers pick up PRs?
- Time to Merge: Once a PR is opened, how long does it take to merge?
- Review Cycles: How many times, on average, does a PR go back and forth between its author and reviewer?
- Code Review Involvement: How is Code Review distributed among Reviewers?
- Code Review Influence: How often do reviews lead to a change in the code or a response? (e.g., How valuable are these reviews?)
Look at these metrics historically to see whether they’ve been increasing or decreasing. You can also look at them in tandem with overall Cycle Time (time between the earliest commit and when a PR is merged to master) to see which have the biggest impact on the team’s speed.
Diagnostic: Distinguish Drivers from Outcomes
A common mistake leaders make when first implementing metrics is looking at outcome metrics and then making assumptions about their Drivers. Often, however, an output metric, such as Cycle Time, is spiking due to an upstream issue. Unclear technical direction, big batch sizes, or a single nit-picky reviewer can all contribute to a high Cycle Time.
Drivers are typically leading indicators. They’re the first quantitative sign that something is going the right direction, and they will, in turn, affect your outcome metrics, which are your lagging indicators. Your leading indicator is representative of an activity or behavior, whereas your lagging indicator is usually a count or a speed, which is the result of that behavior.
In the example we’re using for the piece, here’s how you would split up your metrics:
- Leading Indicator (Driver): Review Cycles, Code Review Involvement, Code Review Influence
- Lagging Indicator (Outcome): Time to Merge
While you diagnose your issue, you’ll want to look at both the Drivers and Outcomes.
Over time, you may discern certain patterns. You might notice that as Code Review Involvement goes up, Code Review Influence goes down. From those data points, you may want to investigate whether overburdening a reviewer leads to undesirable results. Alternatively, you might want to look into teams whose Review Cycles are much higher than others’ (with seemingly no difference in outcome).
Once your team has improved, you can step back from looking at Drivers. Outcomes for your team will serve as at-a-glance indicators for whenever a team or individual is stuck and may warrant your support as a manager.
The Path to High-Performance
The research found in Accelerate suggests that quantitative measures are important—but it also argues that the most successful leaders take a thoughtful and deliberate approach to improving how their organizations work:
“Remember: you can’t buy or copy high performance. You will need to develop your own capabilities as you pursue a path that fits your particular context and goals. Doing so will take sustained effort, investment, focus, time. However, our research is unequivocal. The results are worth it.” – Nicole Forsgren, Jez Humble, and Gene Kim, Accelerate.

This post is the fifth and final article in our Tactical Guide to a Shorter Cycle Time five-part series. Read the previous post here.
If developers’ change sets aren’t always deploy-ready upon merging, your team is not practicing Continuous Delivery.
The final step to fully optimizing your time to market (or your Cycle Time) is to indoctrinate seamless deployment, holding every engineer responsible for keeping the main production branch in a releasable state.
Impediments to true Continuous Delivery fall into three categories:
- Process: Your process involves many manual blockers, including QA and manual deployment.
- Behavioral: Your managers or engineers lack confidence. They’re not sure whether defects will be caught before merging or whether their team can respond to issues uncovered after deployment.
- Technical: Your current tooling is either lacking, too slow, or breaks frequently.
This post will walk you through mitigating each obstacle so that you can achieve a deploy-ready culture on your engineering team.
Work through Process Impediments
Transitioning to a CD process requires every person on your development team to spend their time as strategically as possible. This ruthless approach to time management requires automating everything you can in the deployment process— particularly, any manual phases that completely block deployment.
On many teams, the hardest transition is moving away from a process in which humans gate shipping, such as manual QA and security checks. These stamps of approval exist to give your team confidence that they’re not shipping anything that isn’t up to snuff. To eliminate these blockers, you’ll need to address quality concerns throughout your software dev process—not just at the end.
Remove QA as a Blocker to Deployment
The purpose of testing, whether manual or automatic, is to ensure software quality is up to standard. Many of the practices within CD, such as working in small batches and conducting Code Review, inherently serve as quality control measures. Any major defects that your team doesn’t catch during development should be caught with automated testing.
To reduce the risk associated with removing QA as a blocker:
- Automate testing throughout the software development process (not just at the end). Where and what you test will depend on a multitude of factors, but consider testing as early as possible to ensure developers can make changes before putting in too much work.
- Do not overtest. Overtesting may lead to long build times and will simply replace a manual bottleneck with an automated one. We recommend trying to ensure that test coverage is sufficient enough. If an issue isn’t caught and does break in the middle of the night, it doesn’t require waking up an engineer.
- Use feature flags and dark launches. If there are deployment risks that you have not yet mitigated, use feature flags to roll out changes either internally or to a small sample of your customer base. For further research, check out Launch Darkly’s full e-book on Effective Feature Management.
Once you have these components in place, you’ll want to make sure you have an effective monitoring system, where your tools surface issues as quickly as possible. Measuring Mean Time to Discovery (MTTD) alongside Mean Time to Recovery (MTTR) will help you consistently track and improve the efficiency of both, your monitoring and your pre-deploy testing suite.
Shift Security & Compliance Checks left
Security is one of the most important checks before deployment, which is why you shouldn’t leave it open to human error. Enable your security experts to think strategically about what kind of testing they should run, while leaving much of the tactical security work to the machines.
To integrate security throughout your software delivery process, consider:
- Involving security experts into the software planning and design process. Whenever a feature that handles particularly sensitive data is coming down the Continuous Delivery pipeline, include your security team in the planning and design process. This way, security considerations are baked into the process and front-of-mind for the team as they build out the feature.
- Automated source code scanning (SAST): With 80% of attacks aimed at the application layer, SAST remains one of the best ways to keep your application secure. Automated SAST tools detect all of the most threatening application risks, such as broken authentication, sensitive data expose, and misconfiguration.
- Automated dynamic testing (DAST): Frequently called black-box testing, these tests try to penetrate the application from the outside, the way an attacker would. Any DAST tool would uncover two of the most common risks— SQL injection (SQLi) and cross-site scripting (XSS).
- Automated testing for dependence on a commonly-known vulnerability (CVE): The CVE is a dictionary maintained by the Cybersecurity and Infrastructure Security Agency that you can use as a reference to make sure your automated testing has covered enough ground.
- Building secure and reusable infrastructure for the team. With the above covered, your security team can apply their expertise to create tools for the rest of the team in the form of modules or primitives. This way, they’ll enable developers without security training to write systems that are secure by default.
Naturally, there will always be manual work for your security team, such as penetration testing. If you’re folding security into your development process, however, it won’t become a bottleneck at the very end of the process, stopping features from getting out to customers.
Work through Behavioral Impediments
A survey conducted by DevOps Group found that organizational culture is the most significant barrier to CD implementation.
The behavioral change required to foster a culture of Continuous Delivery is the most difficult, yet the least discussed, aspect of adapting true CD practices. Your team needs to have confidence that their testing infrastructure and ability to respond to changes are strong enough to support Continuous Deployment.
To instill this certainty, you’ll need to create alignment around CD benefits and encourage best practices throughout the software delivery process.
Create Organizational Alignment on Continuous Delivery
If properly communicated, the Continuous Delivery pipeline should not be a hard sell to engineers. CD unblocks developers to do what they like most—building useful software and getting it out into the world.
Three intended outcomes will help you get both managers and engineers invested in Continuous Delivery:
- Less risk. If the testing infrastructure is solid (more on this below), and the developers agree that it’s solid, they will feel more comfortable shipping their changes upon merging.
- Higher impact for the individual developer. When developers have the power to merge to production, they feel more ownership over their work. Due to sheer expectations of speed, the Continuous Delivery pipeline minimizes top-down planning and gives developers the ability to make more choices related to implementation.
- Less blame. Because ownership over a feature isn’t siloed in one individual, the software development process becomes much more collaborative. Distributed ownership over features eliminates some of the anxiety (and potential blame) when developers decide to ship their changes to production.
Equip Your Team for Change with Best Practices
Thus far, our Tactical Guide to a Shorter Cycle Time five-part series has included dozens of best practices that you can share with your team. In addition to these phase-specific optimizations, you’ll also want to coach these general principles:
- Work in small, discrete changes. When developers are scoping a Pull Request, they should be thinking: what is the smallest valuable step I can make towards this feature? When they’ve scoped and built that Pull Request, it should be deployed to production. They should avoid long-running feature branches.
- Always prioritize work closest to completion. Have developers minimize work in progress as much as possible. If you’re using a Kanban board, this means prioritizing items that are closest to done.
Don’t be surprised if this transition process takes over six months. The confidence required from your team will take a long time to build as they become accustomed to this new work style. If you’d like to move quickly, adopt CD with a team of early adopters who are already interested and motivated to make a positive change. You can learn from adoption friction in a small environment to better ease the larger organization transition.
Work through Technical Impediments
Your team can’t overcome either behavioral nor process impediments unless they have confidence in their suite of CI/CD tools. Builds that perform automated testing and deployment should be fast and reliable, while your monitoring set up gives you clear and instant visibility into how things are running.
Sharpen Your Tools
You’re not able to ship features to customers multiple times a day, if either:
- Your build is flakey, or
- Your build is slow.
And even if your tests pass, your team won’t have the confidence to set up automatic deployment, if:
- Your monitoring isn’t thorough, or
- Your monitoring isn’t well-tuned.
Again, a safe way to test the waters is to use dark launches or feature flags. Your team will be able to test how quickly issues are caught and how quickly they can recover—all without compromising the customer experience.
As you work to improve your testing builds and monitoring, we recommend slowly transitioning your manual deploy schedule to a more frequent cadence. Start with weekly deploys, then daily, then multiple deploys a day. Finally, automate the deployment process once pressing the deploy button feels like a waste of time.
The Holy Grail of Software Delivery
Every article in our series has guided you through optimizing each phase in the software delivery process. If you’ve been successful with this, then your developers are making small incremental changes, pushing frequently, and moving work through the Continuous Delivery pipeline with little to no friction.
But unless you’re actually shipping those changes to production, you’re not practicing Continuous Delivery. The point of CD (and Agile before that) was to shorten the feedback loop between customers and engineers. Working incrementally, but still shipping massive releases, does not accomplish this objective.
Deliver continuously to mitigate risk, respond quickly, and get the best version of your software into the hands of customers as quickly as possible.
Check out the other articles in our Tactical Guide to a Shorter Cycle Time five-part series:

This post is the fourth article in our Tactical Guide to a Shorter Cycle Time five-part series. Read the previous post here.
As the engineering industry has moved towards Continuous Delivery, teams have left behind many of the manual quality control measures that once slowed down delivery. Along this same vein, some engineering leaders are doubting whether Code Review still has value:
The annual survey conducted by Coding Bear revealed that 65% of teams are dissatisfied with their Code Review process– yet teams consistently identify Code Review as the best way to ensure code quality. Most people agree Code Review is important, but few know how to prevent it from wasting valuable engineering time.
Before giving up on Code Reviews altogether, we recommend looking at Code Review metrics to identify where you can avoid waste and increase the efficiency of this process.
Defining “Successful” Code Reviews
An effective Code Review process starts with alignment on its objective.
A study at Microsoft a few years ago surveyed over 900 managers and developers to understand the motivation behind Code Reviews. “Finding defects” was the primary motivator of the majority of those surveyed, but when the results were analyzed, the researchers discovered that the outcomes didn’t match the motivations. Improvements to the code were a much more common result of the reviews.
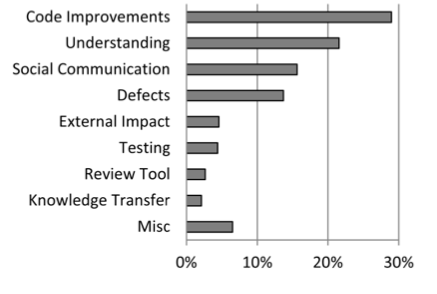
Work with team leaders to determine which outcomes you’re optimizing for:
- Catching bugs and defects
- Improving the maintainability of the codebase
- Keeping consistency of code style
- Knowledge sharing throughout the team
Determining your Code Review priorities helps your team focus on what kind of feedback to leave or look for. Reviews that are intended to familiarize the reviewer with a particular portion of the codebase will look different from reviews that are guiding a new team member towards better overall coding practices.
Once you know what an effective Code Review means for your team, you can start adjusting your Code Review activities to achieve those goals.
Code Review Diagnostics
Historically, there has been no industry standard for Code Review metrics. After speaking with and analyzing work patterns of thousands of engineering teams, we identified the following indicators:
- Review Coverage: the percentage of files changed that elicited at least one comment from the reviewer.
- Review Influence: the percentage of comments that led to some form of action, either in the form of a change to the code or of a reply.
- Review Cycles: the number of back-and-forths between reviewer and submitter.
These metrics were designed to give a balanced representation of the Code Review process, showing thoroughness, effectiveness, and speed. While imperfect (as all metrics are), they provide concrete measures that help you understand the differences between teams and individuals.
Diving into outliers will enable you to finally bring a quality and efficiency standard to Code Reviews across your organization.
Review Coverage
Review Coverage indicates how much attention is spent on reviews and represents review thoroughness. If you’ve identified that the purpose of Code Reviews is to catch defects or improve maintainability, this metric, together with Review Influence, will be a key indicator of how effective this process is.
Low Review Coverage can point you toward incidents of under-review or rubber-stamping. Under-review may be happening as a result of a lack of familiarity with the codebase, disengagement on the part of the reviewer, or poor review distribution.
Unusually high Review Coverage could be an indicator of a nitpicker who’s leading to inefficiency and frustration on the team. This case will likely require realignment on what “good” is.
Review Influence
Any action that is taken as a result of a review comment is proof that the reviewer is taken seriously and their feedback is being considered. When this metric dips low, feedback isn’t resulting in change, indicating that reviews are not perceived to be valuable.
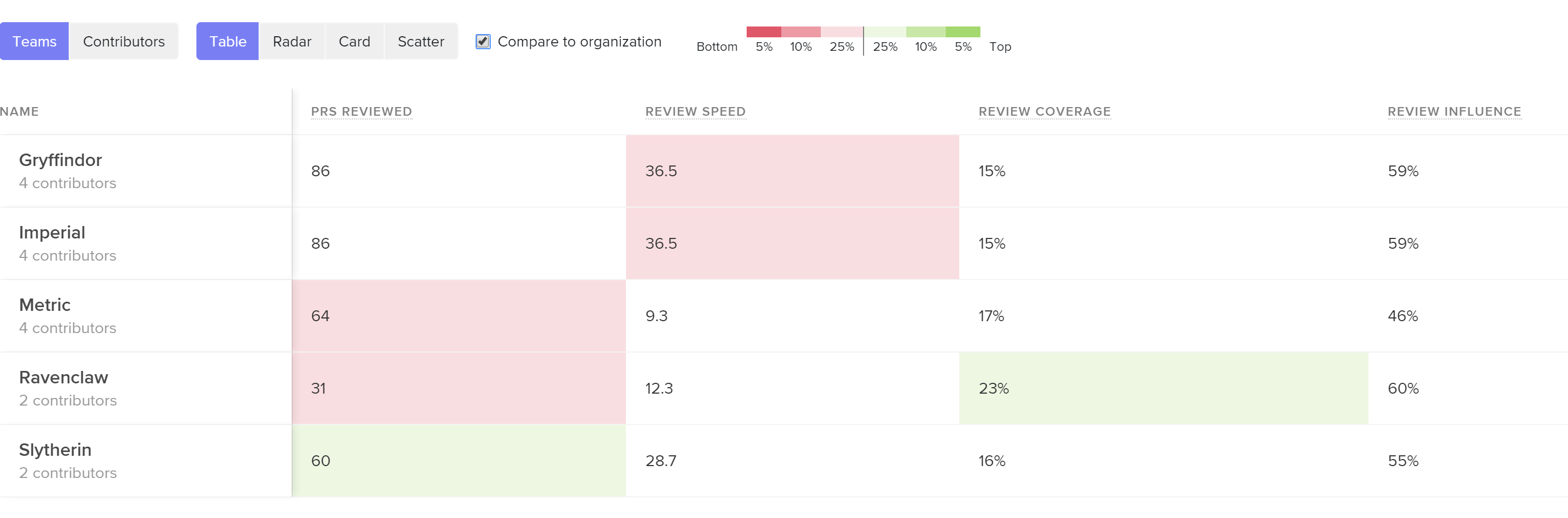
See core Code Review metrics and how they compare across teams or individuals so you can pinpoint the problem.
If you consider this metric in tandem with Review Coverage, you may identify cases where individuals or teams leave many comments (have high thoroughness) but those comments yield no action (are low impact). This can signal that there needs to be a re-alignment on the function or purpose of Code Review.
When the Review Influence is low, you’ll want to dive into the reviews that are being left on each Pull Request. When feedback that was intended to be actioned is ignored, it may indicate that the comments were unclear or the suggestion was controversial.
Review Cycles
Each time a Pull Request is passed back and forth, developers are required to context switch and spend more time on one particular line of work.
If this happens frequently, the review process can become a bottleneck to shipment and directly increase your team’s Cycle Time. Even worse, it can serve as a source of demotivation to engineers and contribute to burnout.
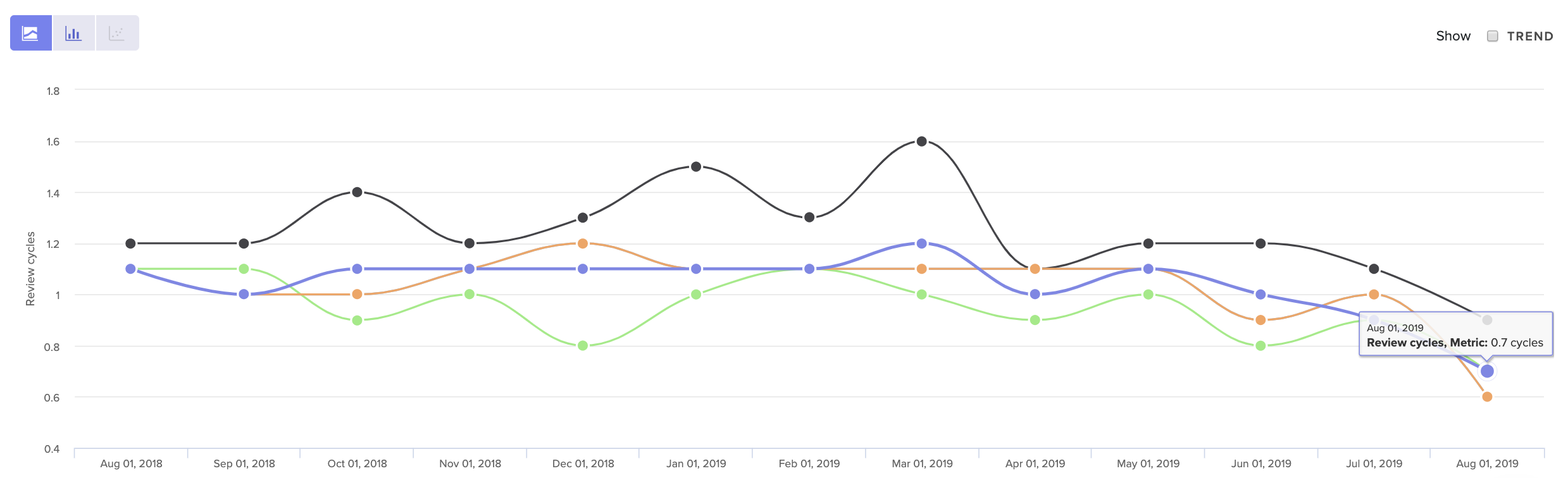
See core Code Review metrics over time, so you can get a sense of what’s normal for your team.
Look at your Review Cycle count over time to get a sense of what is typical for your team. Note that a high number of Review Cycles is typical for less experienced team members who are still becoming familiar with your codebase. Otherwise, when Review Cycles spikes, it typically represents some form of misalignment.
The source of that misalignment could be upstream, due to unclear technical direction. It may indicate that there’s a disagreement about how a solution should best be implemented. Or, more simply, team members may not have clarity about what “done” means.
Bring this data into your retros or 1:1s to start the conversation about where this misalignment may have taken place.
When to Revisit Code Review
Of all the components that influence Cycle Time, Code Review is the most difficult to get right. It requires taking a hard look at metrics, but also frequently requires difficult conversations about how to leave constructive yet respectful feedback. Often, the culture of one team is not conducive to processes have worked well for another.
For this reason, we recommend revisiting your Code Review process after any significant change to processes or team structure. This will get easier after you’ve done it once since you’ll have a clear sense of your expectations and the tools with which to communicate them.
To learn where your team should focus next, check out the other articles in our Tactical Guide to a Shorter Cycle Time five-part series:

This post is the third article in our Tactical Guide to a Shorter Cycle Time five-part series. Read the previous post here.
Every hour that a Pull Request spends awaiting review represents waste–but also threatens to slow down several subsequent lines of work.
An engineer who’s waiting on a code review will move onto the next Pull Request to feel productive until it too gets stuck in the queue. If this pattern continues, reviewers will be faced with a daunting stockpile of unreviewed Pull Requests, and each developer will be juggling three or four simultaneous lines of work. Code review will become a universally painful experience.
A poor Time to First Review (the time it takes for a reviewer to pick up a review) can jeopardize the effectiveness of your entire code review process. Here’s what you can do to mitigate the first significant bottleneck in the software delivery pipeline.
Benchmarking Success
First, you’ll want to define what a “low” Time to First Review means, across the industry and in the context of your organization.
In our analysis of over 19k contributors’ data we uncovered the following benchmarks for Time to First Review:
- The top 25% of engineering organizations get Pull Requests reviewed in under 4 hours.
- The industry median is about one day.
- The bottom 25% take over a day and a half.
You want to lower this metric as much as you can, without it coming at a cost to the focus and productivity of the reviewers. This delicate tradeoff means that you’ll want to understand the dynamics of your specific team before setting metrics-based goals.
First, look at this metric for your organization and team-by-team. Once you know what’s “normal” for your organization, you can further investigate two kinds of outliers:
- Teams with fast reviewers, who have found a way to create an effective process and juggle a difficult team dynamic. Their processes may be worth sharing with the rest of the organization.
- Teams with inconsistent reviewers, who are frequently blocked and struggling to get to code reviews quickly.
From here, dive into individual and team metrics to better understand precisely why your Time to First Review is high or inconsistent.
Time to First Review Diagnostics
Before diagnosing this particular phase of the software delivery process, make sure that it’s not a symptom of an earlier process. (Read our previous post about leveraging Time to Open to better understand how inefficiencies during the first stage can have significant, negative downstream effects.)
If everything earlier in the PR process is streamlined, however, there are three data points you can look at to fully diagnose this slowdown.
Pull Request Size
Pull Request Size is a byproduct of a high Time to Open and usually points to inconsistencies with how your team manages Pull Request scope.
For many teams, opening a Pull Request doesn’t indicate that the changeset is ready for review. Team members tend to continue making changes before the Pull Request gets into the hands of a reviewer.
At this time, a Pull Request can grow, deterring reviewers from picking it up because either A) they aren’t sure if it’s ready, or B) because it has grown in complexity and is, therefore, more difficult to review.
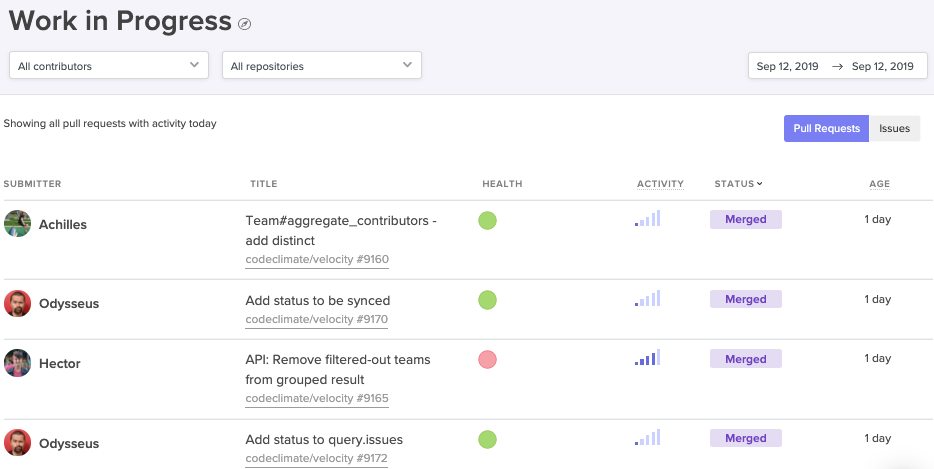
Surface the oldest and most active open PRs, so your frontline managers can mitigate issues before they grow out of hand.
Encourage managers to check in on individual Pull Requests that have been open for longer than a day (but not yet reviewed). If they find patterns among teams or individuals that indicate a lack of scope management, they’ll want to coach their teams on how to control the scope from the onset of the change set, by, for instance, giving PRs titles that are discrete and specific.
Review Workload Balance
Look at Review Involvement (i.e., the percent of reviews that reviewers participate in) across the team to understand how the burden of code review is distributed. If the same few people are handling all the reviews, work will start piling up, creating a lasting bottleneck.
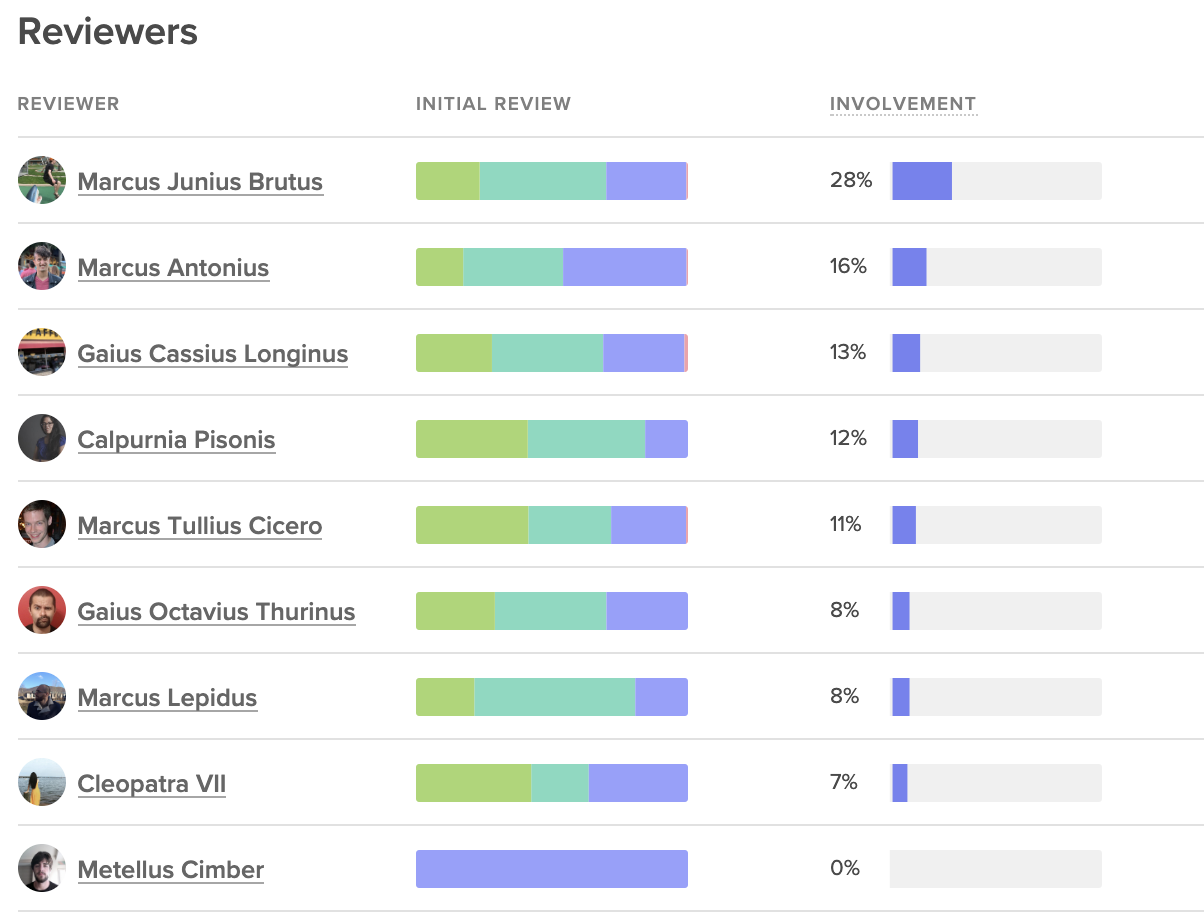
Code Climate's insights show involved each team member is on code reviews, next to the outcomes of those reviews.
Poor distribution may represent a difference of enthusiasm about code review. Some team members may be more keen to pick up reviews, while others consistently prioritize their own coding. This issue can be solved with automated code review assignments or a re-emphasis on code review across the team.
Poor distribution of code reviews can also represent a lack of confidence. The proper response will vary from team to team, but you’ll want to make sure there’s clarity around the expectations of a code review and training on how new team members can ramp up and start participating more deeply in the team-wide collaborative processes.
Review Speed
Unlike Time to First Review, which is used to understand team collaboration patterns, Review Speed is an individual metric, indicating how long each person takes to leave a review.
Review Speed helps you understand how well your team is prioritizing code review.
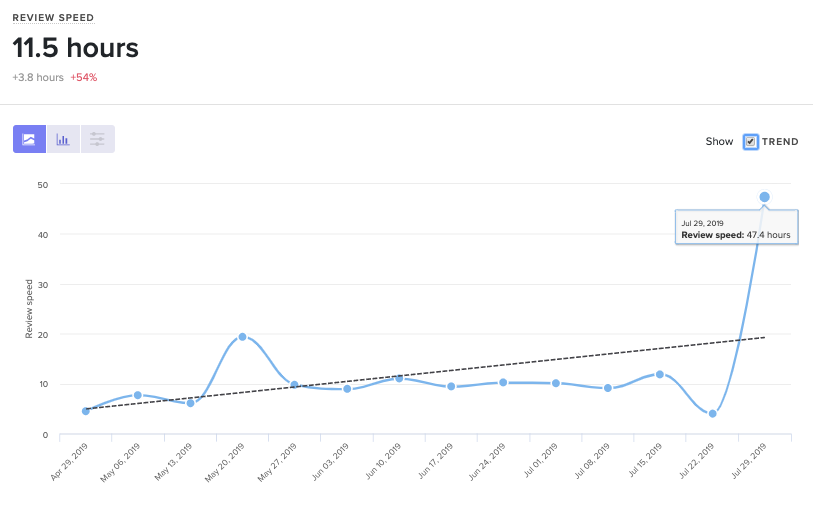
Code Climate's insights can show you how any metric is trending as your team scales or changes.
A high or inconsistent Review Speed can point to cultural or technical blockers.
A cultural blocker can only be uncovered through conversations with specific team members and managers. If you find that a team or a team member is not prioritizing code review, work with them to reprioritize, along with their other responsibilities. Encourage team members to optimize for this metric until Cycle Time decreases and Pull Request authors are quickly unblocked.
A technical barrier at this stage usually indicates that there may be a lack of tooling. Team members, while working in their individual environment, don’t have the signals or alerting systems that inform them of Pull Requests ready for review.
Start Code Review on the Right Foot
Code Review is one of the most difficult processes to get right on a software development team. A different balance between thoroughness and speed exists on most teams– yet few have a solid idea of what their code review objectives should be. Adding an endless queue of unreviewed Pull Requests to this equation makes the entire process unduly more difficult.
If Time to Review is a problem, a small reprioritization or retooling may be necessary– but the effects will be well worth it.
To learn where your team should focus next, look out for the upcoming articles in our Tactical Guide to a Shorter Cycle Time five-part series:

Last Thursday, DORA released their 6th annual State of DevOps report, identifying this year’s trends within engineering departments across industries.
The good news: a much higher percentage of software organizations are adopting practices that yield safer and faster software delivery. 25% of the industry is performing at the “elite” level, deploying every day, keeping their time to restore service under one hour, and achieving under 15% change failure rate.
The bad: the disparity between high performers and low performers is still vast. High performers are shipping 106x faster, 208x more frequently, recovering 2,604x faster, and achieving a change failure rate that’s 7x lower.

Accelerate: State of DevOps 2019
This is the first of the State of DevOps reports to mention the performance of a specific industry. Engineering organizations that worked within retail consistently ranked among the elite performers.
The analysis attributes this pattern to the death of brick-and-mortar and the steep competition the retail industry faced online. Most importantly, the authors believe that this discovery forecasts an ominous future for low performers, as their respective industries grow more saturated. They warned engineering organizations to “Excel or Die.”
There are No Trade-Offs
Most engineering leaders still believe that a team has to compromise quality if they optimize for pace, and vice versa– but the DevOps data suggests the inverse. The authors assert that “for six years in a row, [their] research has consistently shown that speed and stability are outcomes that enable each other.”
This is in line with Continuous Delivery principles, which prescribe both technical and cultural practices that set in motion a virtuous circle of software delivery. Practices like keeping batch size small, automating repetitive tasks, investing in quick issue detection, all perpetuate both speed and quality while instilling a culture of continuous improvement on the team.
Thus for most engineering organizations, transitioning to some form of Continuous Delivery practices shouldn’t be a question of if or even when. Rather, it should be a question of where to start.
The Path Forward: Optimize for DORA’s Four Key Metrics
The DORA analysts revealed that rapid tempo and high stability are strongly linked. They identified that high-performing teams achieve both by tracking and improving on the following four key metrics.
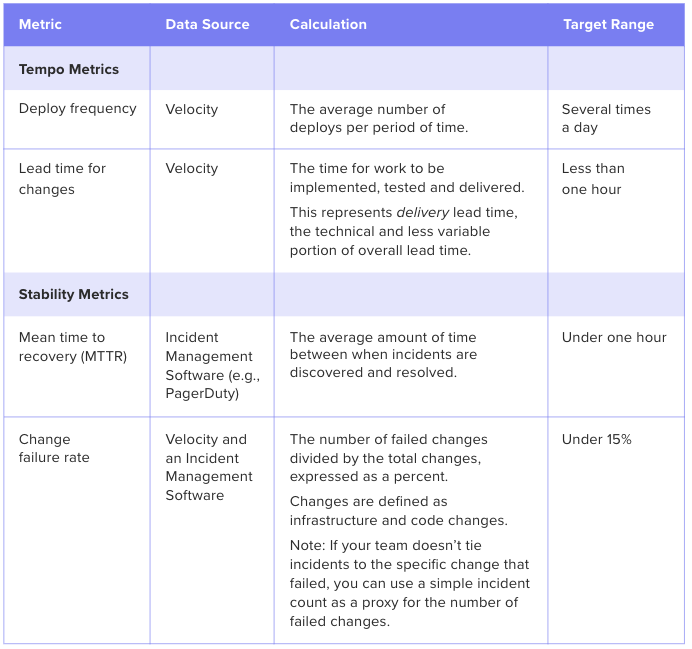
Software Engineering Intelligence (SEI) solutions provide out-of-the-box visibility into key metrics like Deploy Frequency and Lead Time. The analytics tool also reveals underlying drivers, so engineering leaders understand what actions to take to drive these metrics down.

This post is the second article in our Tactical Guide to a Shorter Cycle Time five-part series. Read the previous post here.
You discover your engineering team has a long Cycle Time compared to the rest of the organization or compared to the industry’s top performers. Now what?
When we ran an analysis on 19k+ contributors’ data, we uncovered that of all the identified key drivers, a low Time to Open (time between the earliest commit in a pull request and when the pull request is opened) had the highest correlation to a short Cycle Time.

The correlation coefficient chart above illustrates that Time to Open has the highest impact on overall Cycle Time of all analyzed drivers.
Since Time to Open is a component of Cycle Time, it’s natural to expect some correlation. What’s remarkable, however, is that work practices that take place before a pull request is opened have a higher impact on Cycle Time than those that take place after (including the Code Review process).
This data supports the most important principle of Continuous Delivery: keeping batch sizes small has significant positive downstream effects. By virtue of being small and discreet, each change will easily move through each phase of the software delivery process:
- Review will happen sooner because reviewers perceive the work to be less challenging and time-consuming to review.
- Approval will happen sooner because there will be fewer back-and-forths and the revisions will be less substantial.
- Deploy will happen sooner since less work in progress combined with lower risk encourages developers to deploy quickly.
Time to Open is thus one of the most impactful software metrics and serves as a great starting point for optimizing your Cycle Time.
Scoping the Opportunity for Improvement
Before going in and making changes to improve Time to Open, you’ll want to have an understanding of what “good” looks like. You can look at this metric team-to-team to see how your top performers are doing:
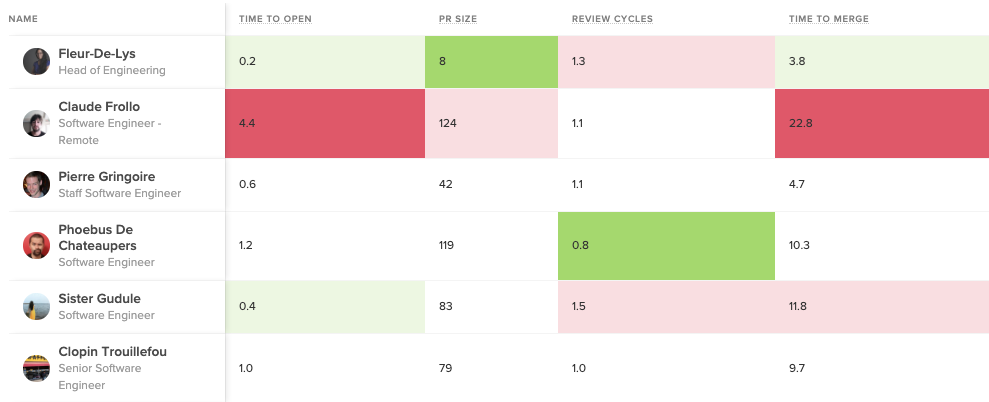
Bright green represents the top 5%, while bright red represents bottom 5% in each metric.
You can also gauge the performance of your entire organization by comparing them to the industry average. This will help you understand your starting point and how to benchmark progress.
Our data analysis reveals the following benchmarks for Time to Open:
- The top 25% of engineering orgs open pull requests in under 3 hours on average
- The industry median is about one day
- The bottom 25% take over two days to open a pull request

Once you know how your teams and your organization as a whole are doing, you can start diving into where, specifically, your team is experiencing friction in the beginning of your software delivery process.
Time to Open Diagnostics
A long Time to Open indicates one or several of three things might be happening on your team:
- Batch sizes are too large, evidenced by the Pull Request Size metric
- There is a high amount of code churn, evidenced by the Rework metric
- There’s a lot of multi-tasking and task-switching, evidenced by the amount of Work in Progress there is at any one given time.
Use the software metrics below as signals in conjunction with qualitative data to understand how to improve your Time to Open.
Pull Request Size
Look at pull request sizes (i.e., batch sizes) to see whether your team is consistently pushing small, easy-to-review changes. Our analysis shows that high-performing teams typically open PRs that are smaller than 150 LOC.
Look at this metric for the entire organization, each team, and then individuals to isolate the problem.
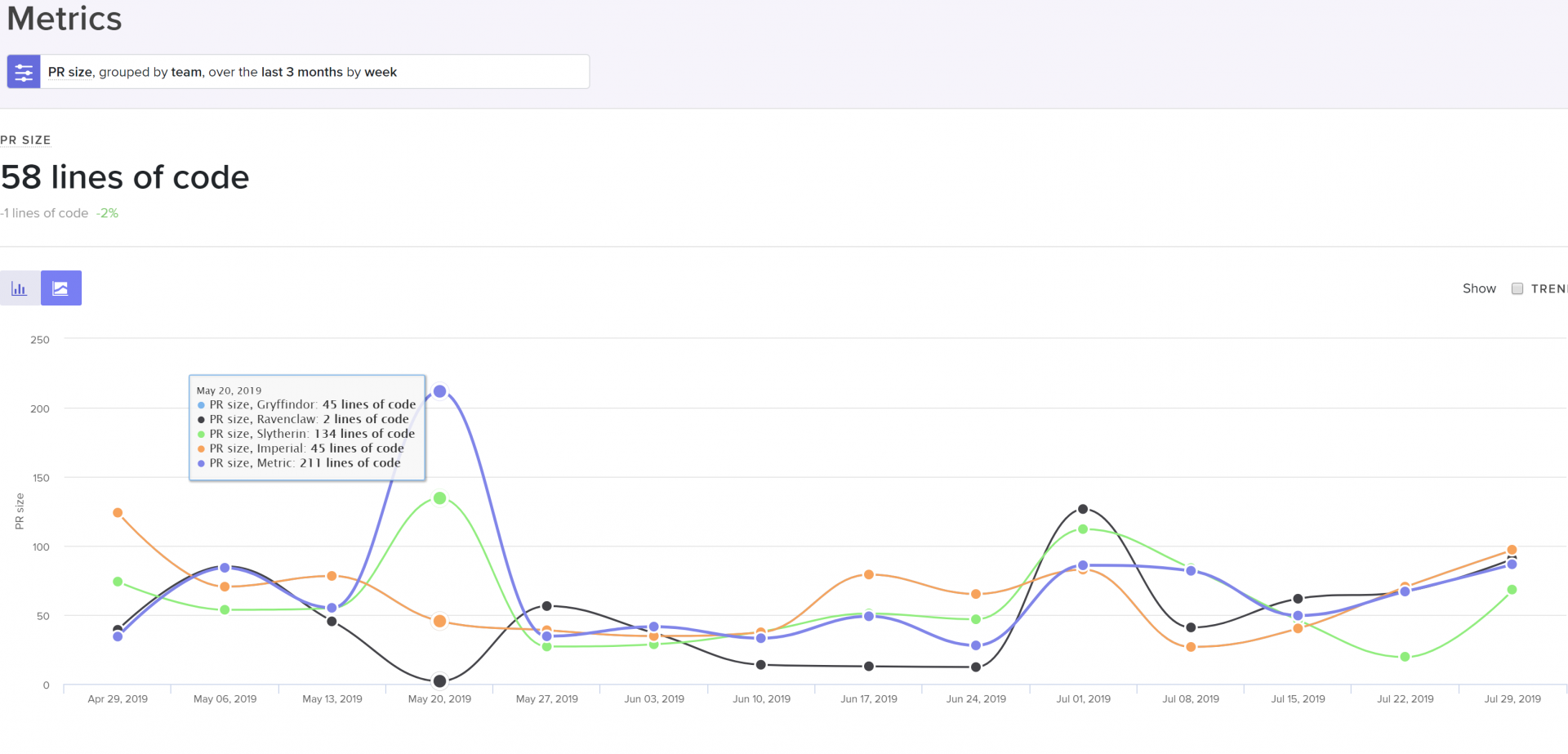
PR size grouped by team, cohort, or individual to help identify the scope of the problem.
If PR Size is high, it may indicate:
- The practice of pushing small batch sizes isn’t viewed as important,
- There’s a lack of experience with keeping batch sizes small,
- Your team hasn’t built up this habit yet
When large PR sizes are systemic across your team or organization, bring this data into discussions with your managers to find out why the team feels comfortable with large changes. Encourage teams to optimize this metric until it drives down Cycle Time and the effects of less bottlenecks are felt.
When this metric is high for an individual, it presents a coaching opportunity. Encourage mentors to show how to approach problems with smaller, more incremental changes.
Rework
We define Rework, or code churn, as a percentage of code changes in which an engineer rewrites code that they recently updated (within the past three weeks). We’ve found that top-performing teams keep their Rework under 4%, but this number can vary.
While some Rework is a natural and expected part of the software development process, high or increased Rework indicates wasted effort that is both slowing down productivity and frustrating engineers.
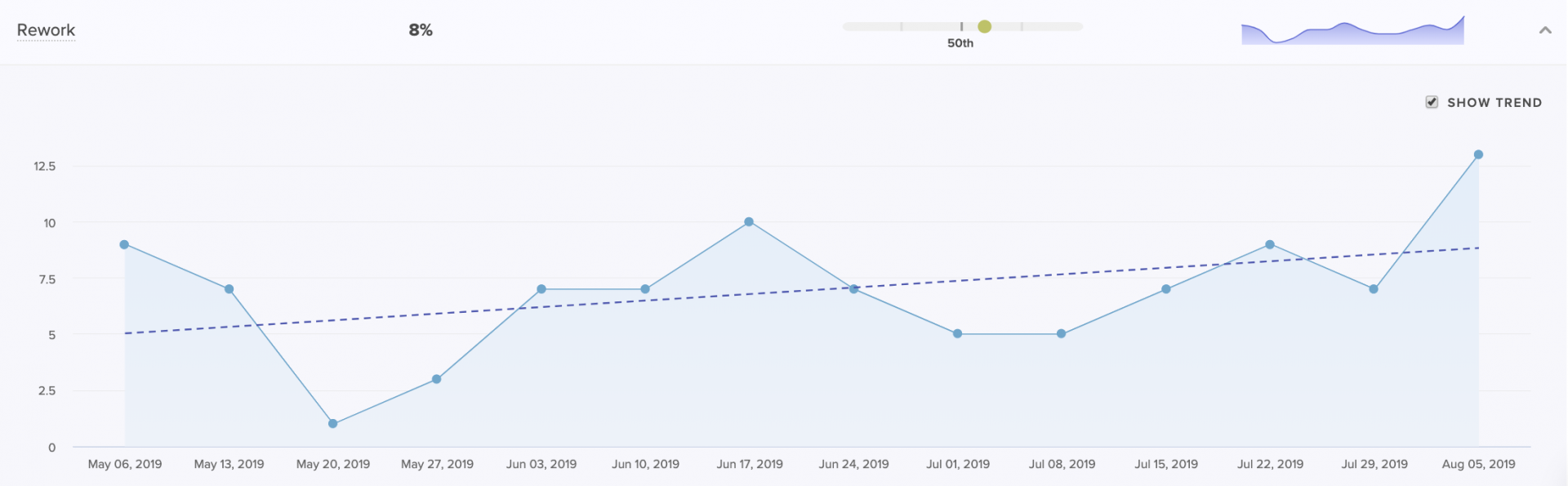
A Coaching Summary for managers to see how Rework of a particular team or individual compares to the rest of the org.
High Rework on the team or organization level can be a signal that there was a misalignment between product and engineering. It often indicates unclear technical direction or consistently late changing product requirements.
When Rework is high for individuals, it’s often a symptom of a lack of experience. Newer team members tend to have higher Rework. If this isn’t decreasing significantly throughout the onboarding of a team member or cohort, consider improving onboarding or mentoring processes.
Work in Progress (WIP)
A principle of lean product development, often discussed in the context of Kanban, is limiting Work in Progress. Practically, this means your team should be consistently progressing the unit of work that is closest to complete so that context-switching is minimal.
Looking at WIP per contributor helps you understand whether your teams are juggling multiple tracks of work, slowing the time to completion for each.
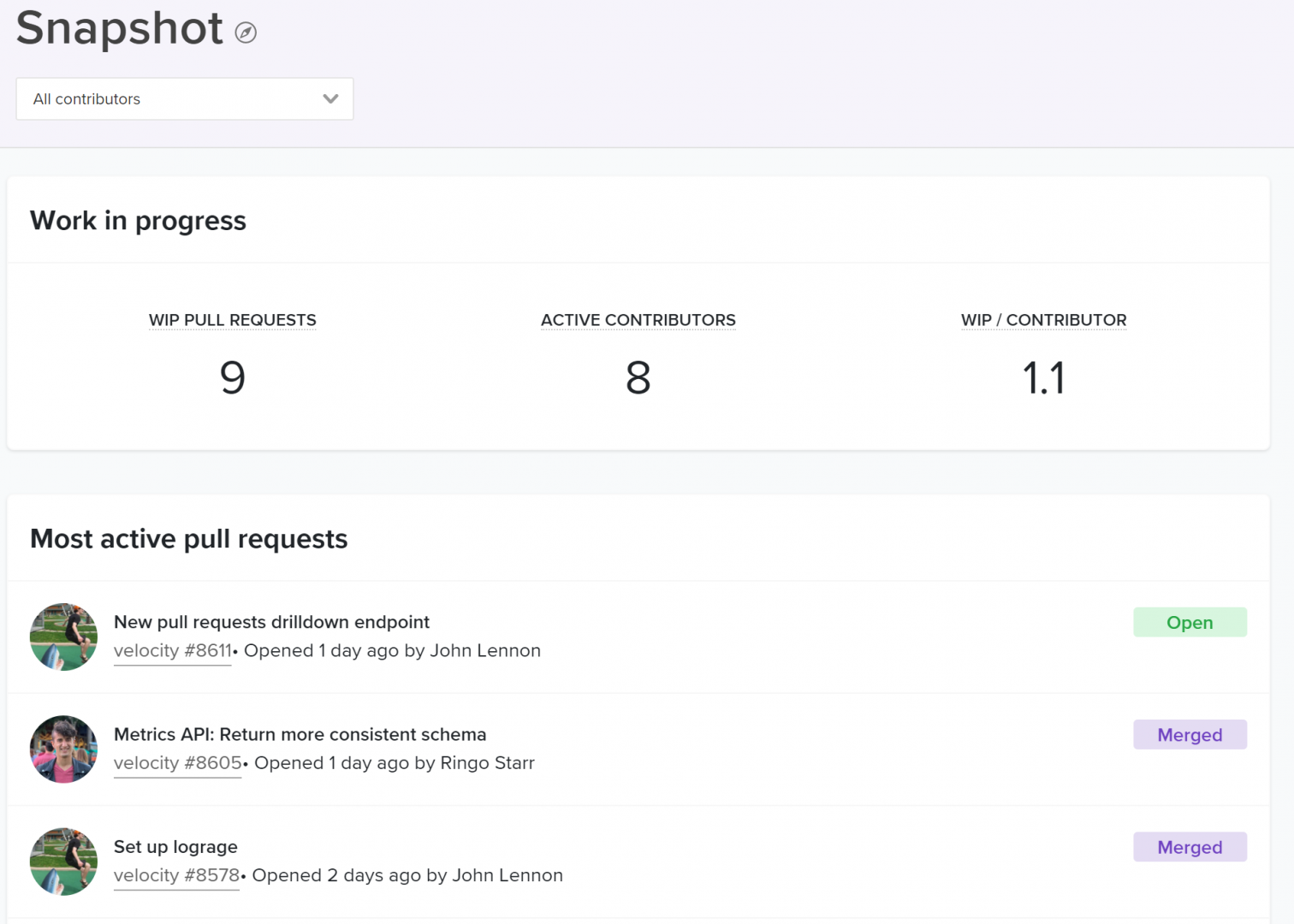
The WIP per contributor with a breakdown of the most active pull requests below.
High WIP for your team or organization is another indication of unclear or conflicting priorities, which cause team members to abandon work and move onto the next project. Similarly, high WIP per Contributor can be systemic in a team with too many dependencies. When team members are constantly blocked, they have no choice but to move forward onto other tracks of work.
High WIP for an individual can be indicative of a bad work habit and should be addressed by mentors or managers through coaching.
What’s Next
The effects of improving Time to Open will immediately improve Cycle Time and team morale. Once engineers feel unblocked and see the impact of their work more frequently, they’ll be eager to uncover more opportunities to further optimize how they work. This will set in motion a Virtuous Circle of Software Delivery which managers can use to facilitate a culture of continuous improvement.
To learn where your team should focus next, stay tuned for the upcoming articles in our Tactical Guide to a Shorter Cycle Time five-part series:

This post is the first article in our Tactical Guide to a Shorter Cycle Time five-part series.
Low Cycle Time is a characteristic of high performing teams–and the authors of 9 years of DevOps Reports have the data to prove it. In their book, Accelerate, they’ve found a direct link between Cycle Time and innovation, efficiency, and positive engineering culture.
Our data analysis of over 500 engineering organizations corroborates their findings. It also reveals helpful benchmarks for teams to gauge how they compare to the rest of the industry. We’ve uncovered that:
- The top 25% achieve a Cycle Time of 1.8 days
- The industry-wide median is 3.4 days
- The bottom 25% have a Cycle Time of 6.2 days
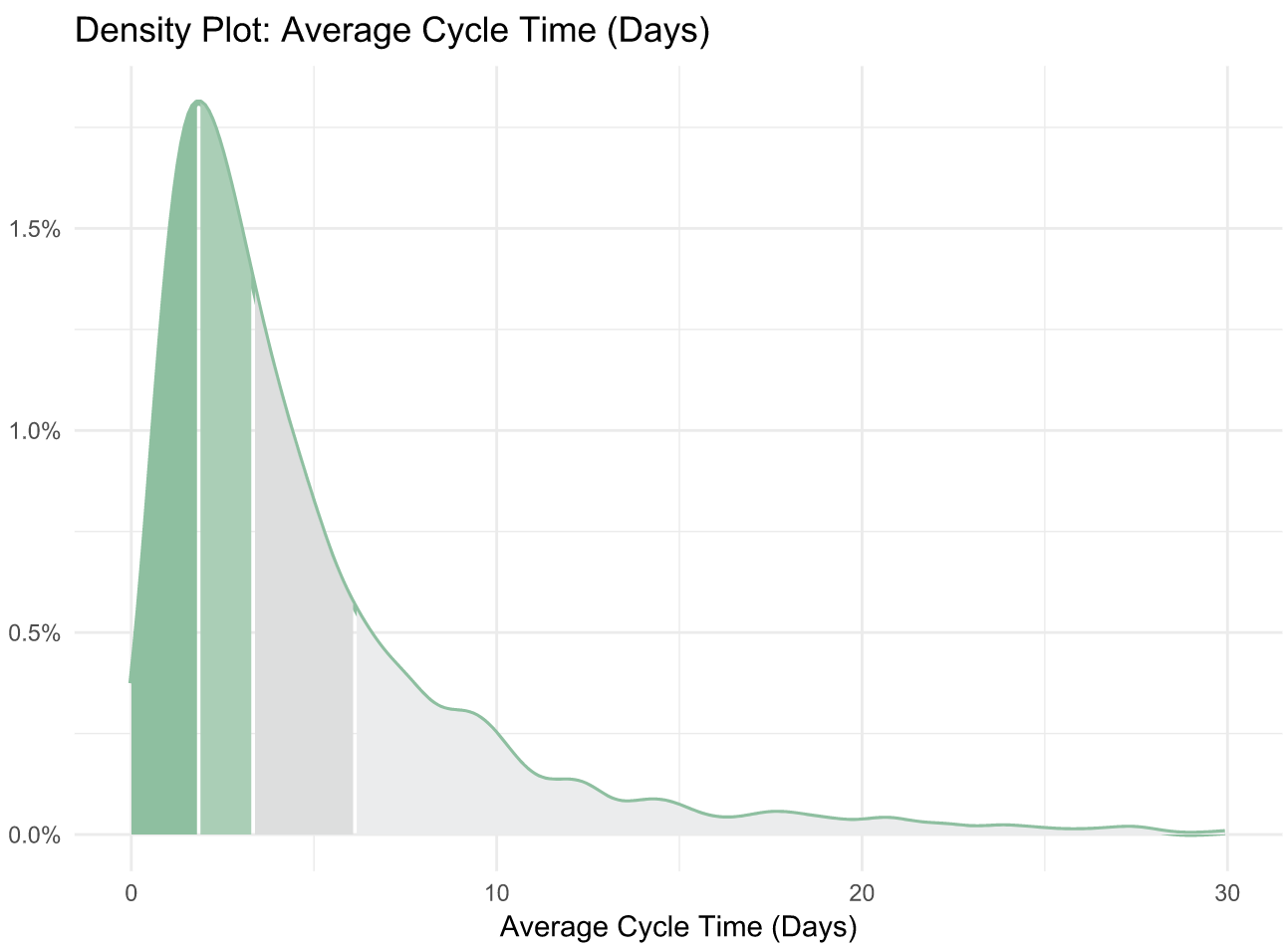
The Accelerate authors discovered the “elite” performers (making up just 7% of the industry) reach a Cycle Time of less than one hour. This means that the median Cycle Time is 80 times higher than that of the best performing organizations. This spread suggests that the majority of the industry either doesn’t measure Cycle Time, doesn’t know what a good Cycle Time is, or doesn’t know how to fix it.
This is why today, we’re kicking off our Tactical Guide to a Shorter Cycle Time, a 5-part series to help you accomplish all of the above.
The Virtuous Circle that Spurs Continuous Improvement
We define Cycle Time as the time between first commit and deploy of a changeset. Whether or not your definition matches ours precisely, optimizing the amount of time between these two events will significantly improve your engineering team’s efficiency (we’ve observed increases of at least 20%).
Measuring and improving this metric has a long term effect that’s even more significant than the initial bump in productivity. It sets in motion a Virtuous Circle of Software Delivery, in which optimization that encourages better engineering practices, paired with the positive reinforcement that comes from unblocking, encourages more optimization that sparks better coding practices, and so on.
The process of improving each portion of your Cycle Time will create a culture of Continuous Improvement on your team.
Where to Start
First, you’ll want to know what your Cycle Time is and how it compares to the industry average.
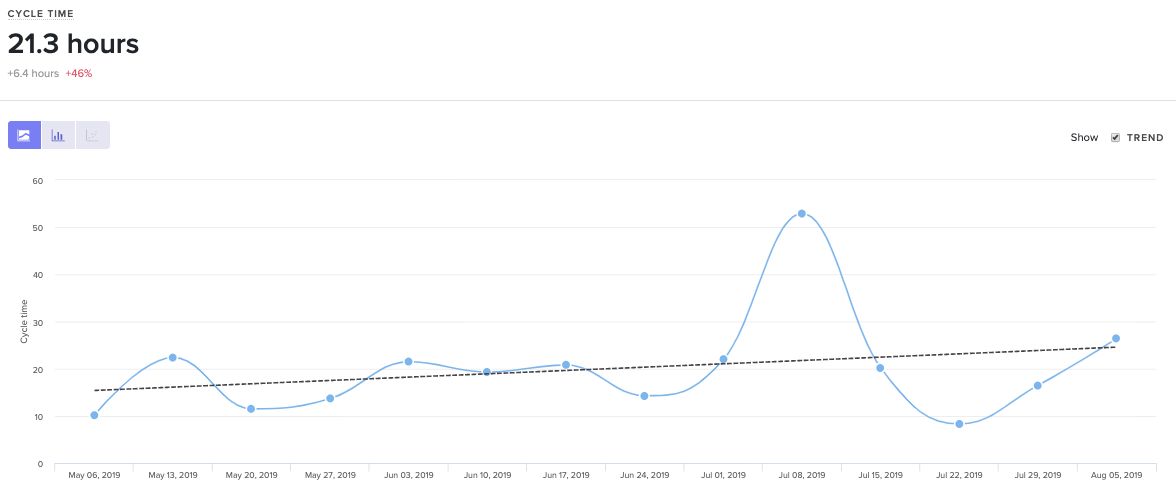
Cycle Time with 3 years of historical data out of the box.
At face value, Cycle Time is a great metric to gauge success, but it isn’t diagnostic. To understand why your Cycle Time is high or low, you’ll want to look at its four constituents:
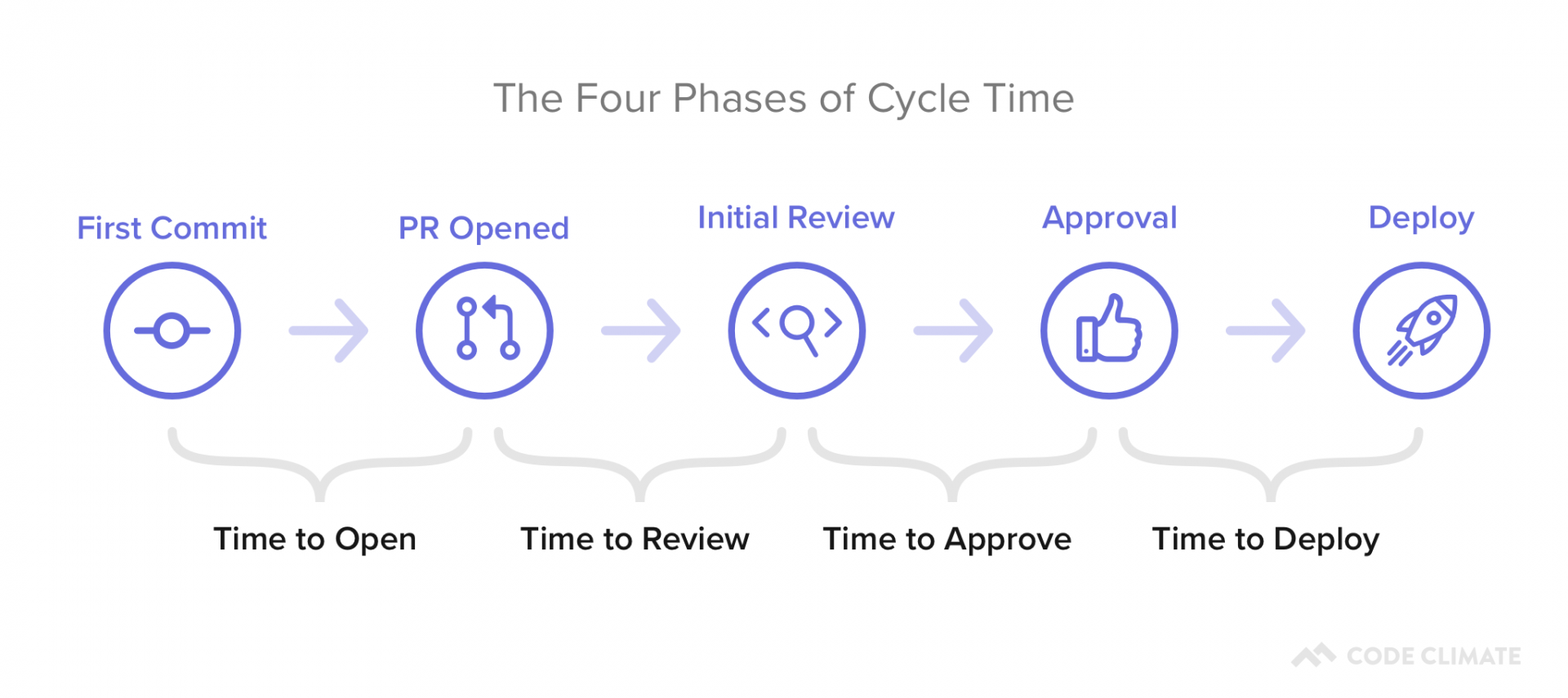
- Time to Open: The time between an engineer’s first commit and when they open a pull request in their version control system. Our data shows that this metric has the highest correlation with Cycle Time, so this is a great place to start optimizing.
- Time to Review: The time between when a pull request is opened and when it receives its first review. Delays at this stage incentivize multi-tasking, so you’ll want to minimize the time a PR is left waiting for review.
- Time to Approve: The time between when a pull request receives its first review and when it is approved, also known as the Code Review process. You don’t want to completely minimize the time spent in this phase, but you do want to make sure you reduce inefficiencies while still getting the value on Code Review you anticipate.
- Time to Deploy: Any additional time following the pull request approval, before the change reaches production.
You can plot these metrics side-by-side and look at them in terms of hours or percentage of time spent, so you know what your team’s starting point is before optimizing.
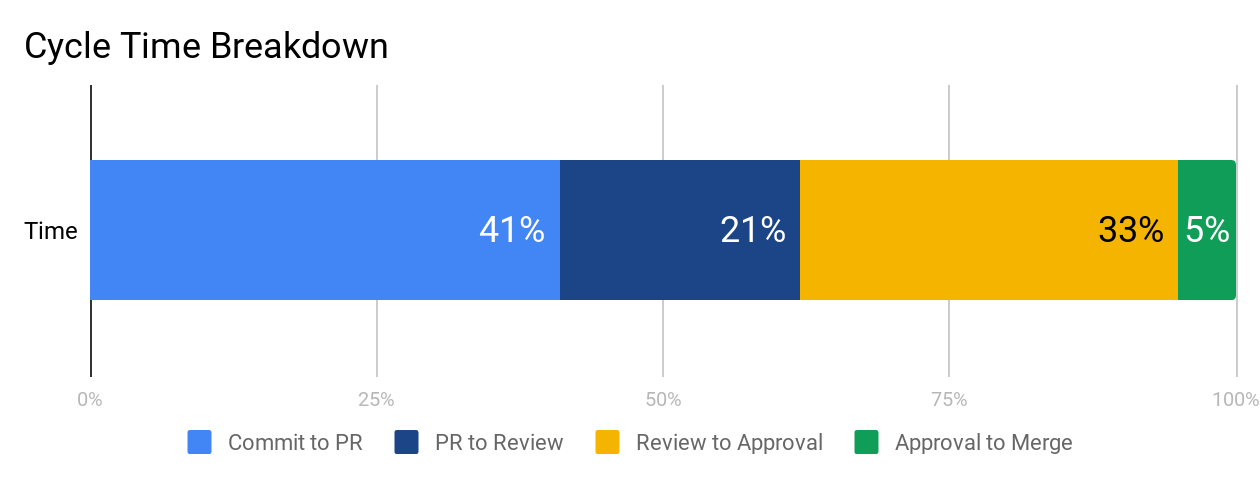
We recommend working on each phase from left to right because inefficiencies tend to compound from earlier stages. When a very large pull request is opened, it also affects how long it’ll wait for review and how likely it is to get stuck in the code review process. Start with Time to Open to ensure your team has streamlined individual practices before moving on to collaborative ones.
What’s Next
The next four parts of our series will dive deep into each component of Cycle Time:
- Part I: The Virtuous Circle of Software Delivery
- Part II: The Single Greatest Lever in Shortening Cycle Time
- Part III: How to Stop Code Review from Bottlenecking Shipping
- Part IV: Keep Code Review from Being a Waste of Everyone’s Time
- Part V: The Last Mile to True Continuous Delivery
We’ll include industry benchmarks, based off our analysis of 500+ engineering teams’ data, further data points to investigate, and tactical advice on how to improve each stage.

A retrospective is a time for our team to look back. Its function, however, is to improve the way in which we move forward. Let’s digest the original definition from Scrum:
“The Sprint Retrospective is an opportunity for the Scrum Team to inspect itself and create a plan for improvements to be enacted during the next Sprint.”
The first two components are activities, the third is a result. And while most teams have fruitful conversations and create action items to yield that result, few have systems in place to ensure that positive change is actually created.
- Inspect ✔
- Create a plan ✔
- Enact improvements 🤷♀️
The problem starts with the notion of “improvement.” It’s both vague and subjective, so any plan of activities feels like a step in the right direction (spoiler: it’s not). If you take measures to concretely define improvement, however, you can hold yourself and your team accountable to your action items. For that, we can use SMART goals.
SMART goals contextualize improvement
Research has shown that goals that are both specific and time-bound are considerably more likely to yield results than generic action items.
Putting a number and a date to each retrospective action item ensures:
- The department understands and aligns on what constitutes success, and
- Progress towards this goal is black and white – trending toward or away from the goal.
While there are plenty of systems that put a number and date to goals, but for the sake of this post, we’ll stick to one that’s tried-and-true: SMART (Specific, Measurable, Achievable, Relevant, Time-bound) goal-setting.

To best position your team to work with SMART goals, you’ll need to adjust all three components of the retro. You’ll be inspecting with more data, creating a plan using SMART goals, and enacting improvements by making progress transparent to everyone on the team.
Inspect: Use data to diagnose the biggest issues
Most teams decide on goals using only qualitative feedback. A team member raises what they perceived to be a large bottleneck, and the whole team immediately starts trying to mitigate that issue. This method gives precedence to what individuals remember and feel, not necessarily the largest and most pressing problems. While personal and anecdotal experience is vital to understanding how a problem affects the whole team, it doesn’t tell the whole story.
If you bring more data points into diagnosing the problem, however, you’re more likely to get a holistic understanding of each bottleneck. Quantitative data helps counteract recency bias and enables you to prioritize based on actual risk that the problems present to your team’s productivity.
Let’s say a given engineering team is trying to diagnose why they didn’t get to as many features as they anticipated this sprint. One engineer, Hannah, makes the following hypothesis:
I feel like there were more pull requests than usual that were open at any one given time. I think it’s because people were too busy to get to code reviews, so work piled up.
Several engineers nod their head. They also noticed that there were more open PRs than usual in GitHub.
Instead of immediately brainstorming action items, Hannah and her team investigate further. They start by looking at their Time to Review this past sprint, and realize it’s relatively low – just 6 hours. This is contradictory to Hannah’s assessment that the review process was slower than usual. From there, they see that their average number of Review Cycles is about 1.2, where most Pull Requests are approved after one review. Also, seems pretty good.
Finally, they found a red flag when they looked at their Time to Merge. They realize that many pull requests stay open for a long time after they’re reviewed as developers move on to new tracks of work. They then agreed to create a target for open lines of work, so that each team member would only work on one feature at a time.
The gut instinct of the team recognized the symptom– long running pull requests– but not the cause. Without data, they couldn’t have uncovered and addressed a deeper systemic problem.
Other data points you may consider looking at:
- All recent activities, including Pull Requests, Code Reviews, and Tickets, to remind your team of what they worked on last sprint, and where they might have gotten stuck.

Activity Log represent every engineering activity with a shape.
- The most important pull requests last sprint. Look at pull requests that had a big effect on the codebase, as well as pull requests that were larger or older than the rest.
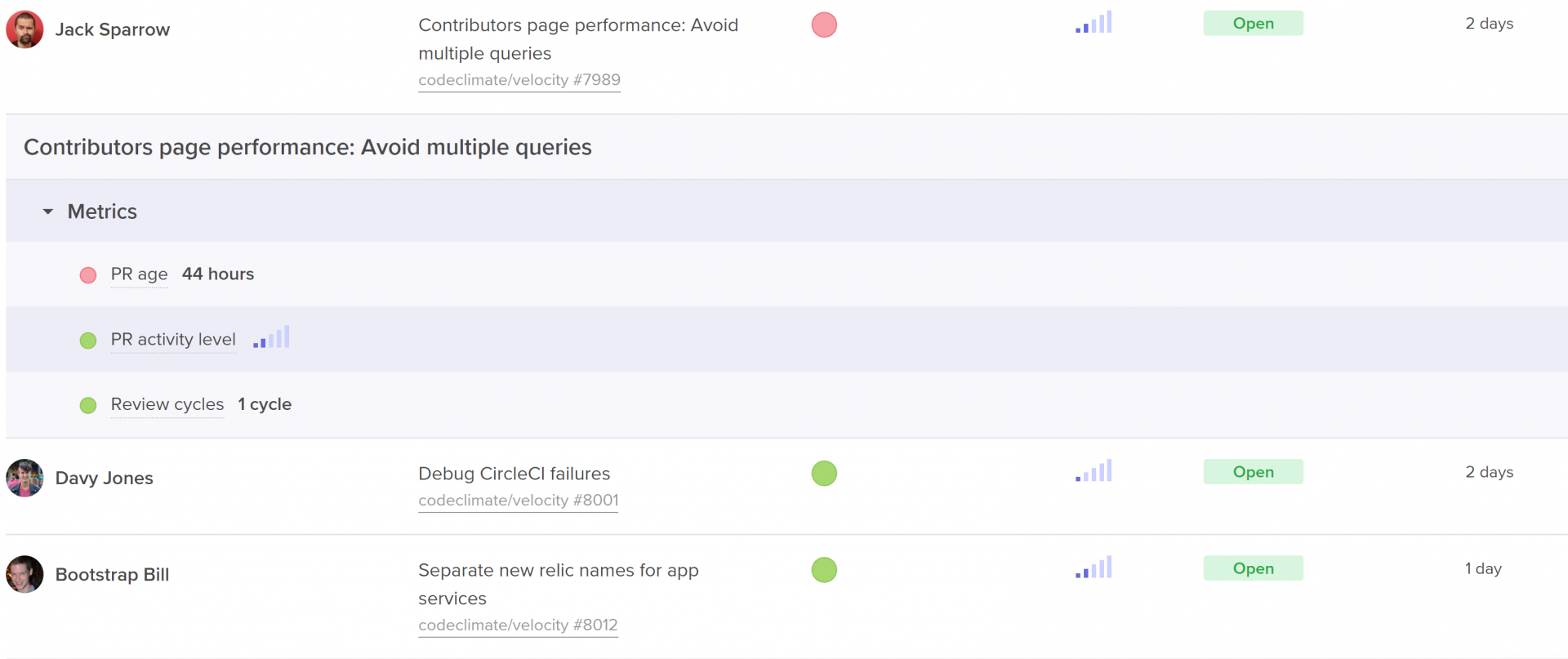
Code Climate's insights show work in progress with activity level, age, and health.
- Process metrics including outcome metrics like Cycle Time and Pull Request Throughput, but also metrics that represent more specific areas of the software development process, like Time to Open, Time to Review, and Time to Merge.
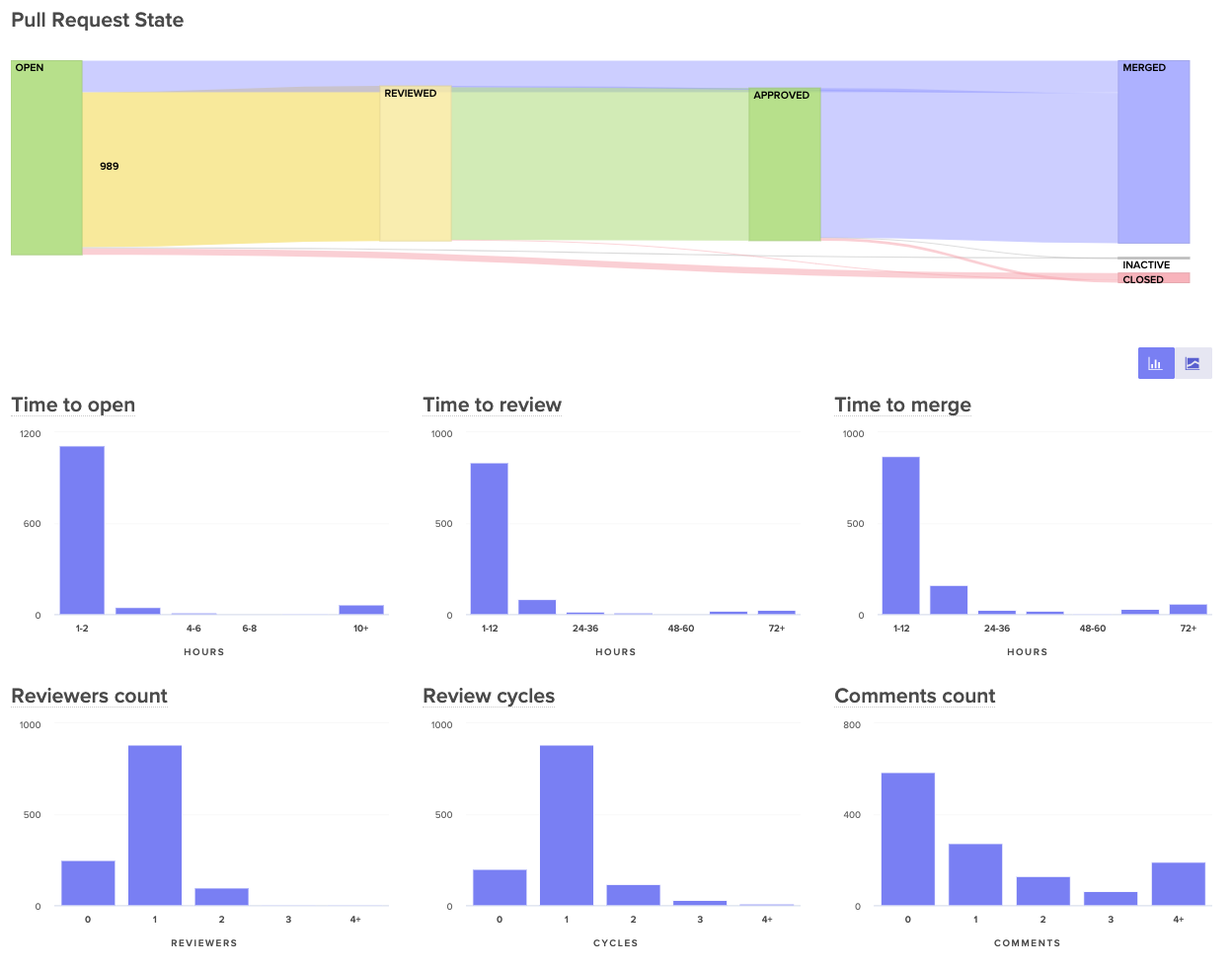
Visualize the journey of your pull requests from open to merged. Below, you can see metrics that represent constituents of this journey to better diagnose slowdowns.
Plan: Align with SMART goals
Once your team has fully diagnosed an issue using both qualitative and quantitative data, they’ll have to decide on one, specific metric that they can use as their SMART goal.
Specific
Success of hitting or missing your metric should be black or white, so you need a concrete number in your goal. “Improving our Time to Review” is vague, “Decreasing our Time to Review to under 4 hours” is specific.
Also, make sure the metric is narrow enough that the team knows which behaviors drive this metric up or down. Metrics that are too broad can obscure progress since they’re affected by many different kinds of unrelated data. Hannah’s team, for example, would want to choose a metric like Time to Merge, rather than total Cycle Time, so the team can easily self-correct when they notice the metric trending in a negative direction.
Measurable
The way in which you measure your metric depends on your objective. If you’re measuring output, for example, a simple count can do the trick. If you’re looking to adhere to specific standards– such as keeping pull requests small, or keeping downtime minimal– you’ll want to decide between tracking the simple average and tracking it as a sort of Service Level Objective (SLO) based on a percentile.
Here are a few examples:
Average Target
SLO Target
Decrease Pull Request Cycle Time to under 1 day.
90% of pull requests should have a cycle time of under 1 day.
Decrease Pull Request Size to an average of 250 lines of code.
Keep 95% of pull requests under 250 lines of code.
Reduce Review Cycles to an average of 1.5 cycles.
Keep 90% of reviews to one cycle.
Reduce Review Speed to an average of 1 hour.
Keep 90% of reviews to under 1 hour.
While averages are more commonly used in process metrics, SLOs enable your team to deviate from the goal in a few instances without hindering their ability to meet the target.
Assignable
Pick one person to own and track this goal. Research has shown that having exactly one team member check in at regular intervals drastically increases the chances that a goal will be hit. Apple championed the idea of a Directly Responsible Individual (DRI) for all initiatives, and teams at leading tech companies like Microsoft have applied the DRI model to all DevOps related functions.
Ownership will also help you secure buy-in for bringing data into retros. Consider asking the person who uncovered the problem in the first place to own the goal.
Realistic
Make sure your goal is reachable, so your team feels success if they’ve put a concerted effort into reaching the goal.
Execute: Increase visibility to keep goals front of mind
The true test of your action items come after the retro. How frequently will your team think about these metrics? Will success be known across the team? If your team is unsuccessful, will they be able to try a different adjustment?
To keep the goal front of mind, you need to make progress visible to everyone on the team. Many managers use information radars, either in shared spaces or in universally accessible dashboards.
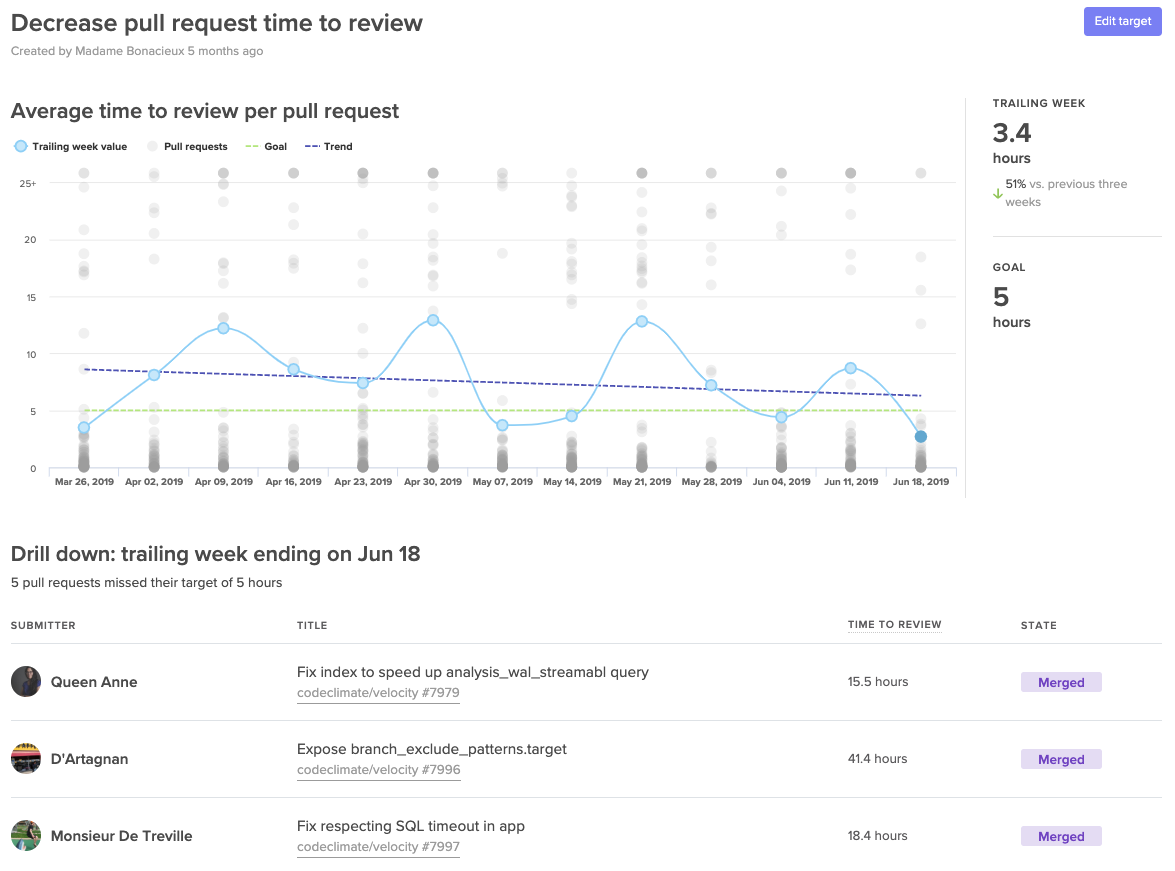
A Target dashboard that lets you visualize progress towards your SMART goals.
Making progress transparent equips the team to bring the results-oriented discussions outside of their retros. Effective goals will be brought up during standups, 1:1s, and even pairing sessions. Repetition will secure focus and will further unify the team around success.
📈 makes engineers 😊
When Boaz Katz, the founder and CTO of Bizzabo, started setting concrete targets he found that sharing success motivated his team to find more ways to improve. He told us, “My team developed a winning attitude and were eager to ship even faster.”
When the whole team sees success each retro, the momentum creates a flywheel effect. Team members are eager to uncover more improvement opportunities creating a culture around enacting positive change to your processes.