python/examples/integrations/fastapi/README.md
# ⚡ Monitor ML Models with FastAPI, Scikit-learn, whylogs, and WhyLabs
FastAPI is a modern, fast (high-performance), web framework for building APIs with Python. It's easy to learn, fast to code, ready for production, and is widely used for machine learning and data science applications.
whylogs can be easily integrated into a FastAPI project to perform data and ML monitoring in real-time.
## 📖 Example Overview:
This example shows how to write whylogs data profiles to WhyLabs for monitoring a machine learning model with FastAPI and scikit-learn. If you'd like to save whylogs profiles to a local directory instead of WhyLabs, use `why.write(profile,"profile.bin")`.
There are two notable files in this example:
- `train.py` - trains and saves an example kNN model with scikit-learn and the iris dataset.
- `api.py` - Create a model prediction API endpoint with FastAPI and write data profiles to WhyLabs for ML monitoring with whylogs.
## 🛠️ How to implement ML monitoring for FastAPI with whylogs and WhyLabs:
First we'll import the necessary libraries, load the ML model, define class names, and set the WhyLabs variables.
To get the WhyLabs API key and ord-id, go to the [WhyLabs dashboard](https://hub.whylabsapp.com/) and click on the "Access Tokens" section in settings. Model-ids can be found under the "Project Management" section.
```python
import joblib
from fastapi import FastAPI
from pydantic import BaseModel
from fastapi.encoders import jsonable_encoder
from fastapi.responses import JSONResponse
import os
import whylogs as why
# Set class names for prediction
CLASS_NAMES = ["setosa", "versicolor", "virginica"]
# Load model
model = joblib.load('knn_model.pkl')
# Set WhyLabs variables
os.environ["WHYLABS_DEFAULT_ORG_ID"] = "ORGID"
os.environ["WHYLABS_DEFAULT_DATASET_ID"] = "MODELID"
os.environ["WHYLABS_API_KEY"] = "APIKEY"
app = FastAPI()
```
> PRO TIP: A best practice for software deployment is to have these environment variables always set on the machine/environment level (such as per the CI/QA machine, a Kubernetes Pod, etc.) so it is possible to leave code untouched and persist it correctly according to the environment you execute it.
Next we'll create a Pydantic model for the input data and a prediction function. The prediction function will make a prediction with the model and return the predicted class and probability score.
Finally, we'll create an prediction API endpoint with FastAPI that will also log the input + prediction data with whylogs and write the data profile to WhyLabs.
```python
# Create Pydantic model for input data
class PredictRequest(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
# Create prediction function
def make_prediction(model, features):
results = model.predict(features)
probs = model.predict_proba(features)
result = results[0]
output_cls = CLASS_NAMES[result]
output_proba = max(probs[0])
return (output_cls, output_proba)
# Create API endpoint
@app.post("/predict")
def predict(request: PredictRequest) -> JSONResponse:
# Convert input data to list for model prediction
data = jsonable_encoder(request)
features = list(data.values())
# Make prediction with model & add to data dictionary
predictions = make_prediction(model, [features])
data['model_class_output'] = predictions[0]
data["model_prob_output"] = predictions[1]
# Log input data with whylogs & write to WhyLabs
profile_results = why.log(data)
profile_results.writer("whylabs").write()
return JSONResponse(data)
```
You can now make a prediction request to the API endpoint. The input data will be logged with whylogs and written to WhyLabs for ML monitoring.
## 🚀 How to run the example:
### 1. Install dependencies
```bash
pip install -r requirements.txt
```
### 2. Train the model
This will train and save an example model as `knn_model.pkl`
```bash
python train.py
```
### 3. Run the API server
First update the WhyLabs variables in `api.py` with your own values. Then run the API server.
```bash
uvicorn api:app --reload
```
### 4. Make a prediction request
You can use the following cURL command to make a prediction request to the API endpoint or use the swagger UI at `http://localhost:8000/docs`.
```bash
curl -X POST "http://localhost:8000/predict" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"sepal_length\": 5.1, \"sepal_width\": 3.5, \"petal_length\": 1.4, \"petal_width\": 0.2}"
```
### 5. View the logged data in WhyLabs
Go to the [WhyLabs dashboard](https://app.whylabsapp.com/) and click on the project setup for logging.
Once profiles are written to WhyLabs they can be inspected, compared, and monitored for data quality and data drift.

Learn more about how to use WhyLabs to monitor your ML models in production [here](https://docs.whylabsapp.com/).
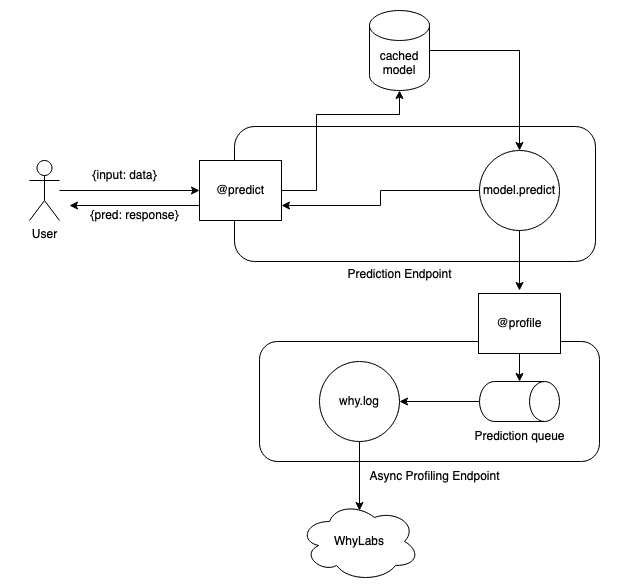
## A decoupled architecture approach to ML monitoring
In general, whylogs is [quite fast](https://whylabs.ai/blog/posts/data-logging-with-whylogs-profiling-for-efficiency) with bulk logging, but it does have fixed overhead per log call, so some traffic patterns may not lend themselves well to logging synchronously. If you can't afford the additional latency overhead that whylogs would take in your inference pipeline then you should consider decoupling whylogs.
Instead of directly logging the data on every call, you can send the data to a message queue like SQS to asynchronously log.
## Get in touch
In this documentation page, we brought some insights on how to integrate a FastAPI prediction endpoint with WhyLabs, using whylogs profiles and its built-in WhyLabs writer. If you have questions or wish to understand more on how you can use WhyLabs with your FastAPI models, join our [Slack community](http://join.slack.whylabs.ai/) or [contact us](https://whylabs.ai/contact-us).