Productivity

Your engineering speed is your organization’s competitive advantage. A fast Cycle Time will help you out-innovate your competitors while keeping your team nimble and motivated. It’ll help you keep feedback loops short and achieve the agility necessary to respond to issues quickly. Most importantly, it’ll align everyone – from the CTO to the individual engineer – around what success means.
To discuss Cycle Time and its implications, we invited a panel of engineering leaders and industry experts for a virtual round table.
Code Climate Founder and Former CEO, Bryan Helmkamp, was joined by:
- Bala Pitchandi, VP of Engineering at VTS
- Katie Womersley, VP of Engineering at Buffer
- Bonnie Aumann, Remote Agile Coach at CircleCI
Over the course of the hour, these panelists covered topics such as using metrics to design processes that work for your team, building trust around metrics, and tying delivery speed to business success.
Here are some of the key takeaways:
Prioritize innovation over semantics.
Bryan Helmkamp: When I think about Cycle Time, I think about the time period during which code is in-flight. And so I would start counting that from the point that the code is initially written, so ideally, the time that that code is being typed into an editor and saved on a developer’s laptop or committed initially, shortly thereafter. Then I would measure that through to the point where the code has reached our production server then deployed to production.
Bala Pitchandi: I define Cycle Time as when the first line of code is written for a feature — or chore, or ticket, or whatever that may be — to when it gets merged.
Bryan Helmkamp: I think it’s also important to point out that we shouldn’t let the metrics become the goal in and of themselves. We’re talking about Cycle Time but really, what we’re talking about is probably more accurately described as innovation. And you can have cases where you’ll have a lower Cycle Time, but you’ll have less innovation. It can be a useful shorthand to talk about (e.g., we’re going to improve this metric), but really that comes from an objective that is not the metric. It comes from some shared goal. That understanding matters much more than the exact specific definition of Cycle Time that you use because really you’re going to be using it to understand directionality: are things getting better? Are they things getting faster or slower? Where are the opportunities to improve? And for that purpose, it doesn’t really matter all that much whether it’s from the first commit or the last commit or whether the deploy is included; you can get a lot of the value regardless of how you define the sort of thing.

The faster you fail, the faster you innovate.
Bala Pitchandi: When I was pitching this to our executive team and our leadership team, I used the analogy of Amazon and Walmart. Most people think that Amazon and Walmart are competing against each other on their prices. But keeping aside the technology parts of Amazon, they’re basically retailers. They both sell the same kind of goods, more or less, but in reality, they’re competing against each other on their supply chain. In other words, you could sell the same goods, but if you have a better supply chain, you can out-execute and be a better business than the other company, which may be doing the exact same thing as you are. And I think that I was able to translate that to the software world by pointing out that we could be building the same exact software as another company, but if we have a better software delivery vehicle or software delivery engine, that will result in better business goals, business revenue, and business outcomes. That resonated well, and that way, I was able to get buy-in from the leadership team.

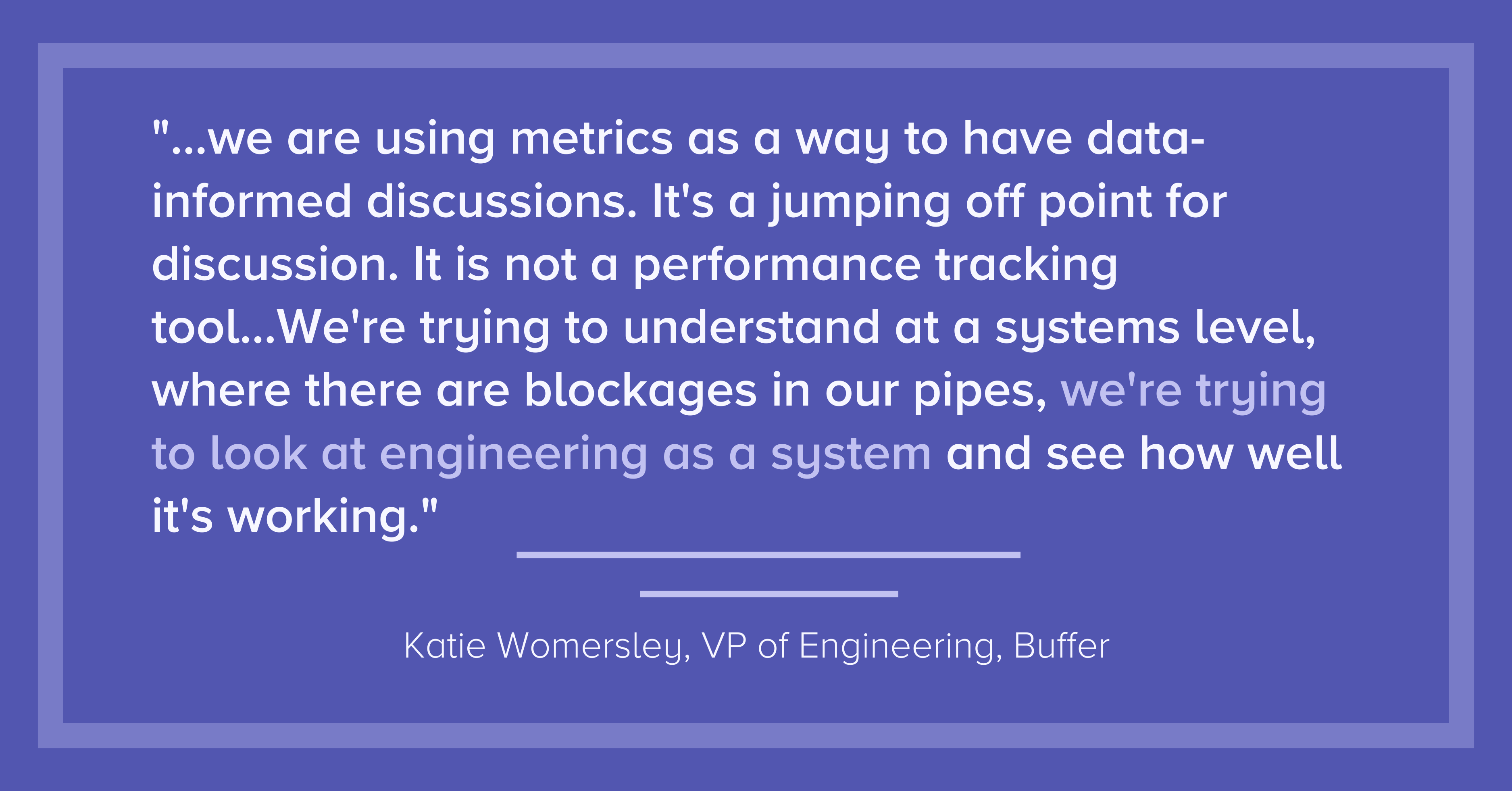
Katie Womersley: The most interesting business discovery we’ve had from using Cycle Time has been where it’s been slow. It’s been a misunderstanding on the team about what is agile, where we’ve thought, “Oh, we’re very agile.” Because we’ve had situations where we’re actually changing what we’re trying to ship in PRs — we’re reworking lines of code because we think that we’re evolving by collaborating between product managers and engineers with the PM changing their mind every day about what exactly the feature is. And the engineer says, “I’ll start again, I’ll start again, I’ll start again.” And the team in question felt this was just highly collaborative and extremely agile, so that was fascinating because, of course, that’s just not effective at all. You’re supposed to actually get something into production and then learn from it, not just iterate on your PRs in progress. We actually need some clarity before we start coding, and I do believe that that had business impact on knowing what we were shipping.

Bala Pitchandi: We believe in this concept of failing fast. We want to be able to have a small enough Cycle Time to ship customers something quickly. Maybe it’s a bet on the product side, and wanting to ship it fast, sooner and get it into the customer’s hands, our beta users hands, and then see if it actually sticks and if we’ve been able to find the product market fit. That failing fast is really valuable, especially if you are in the early stage of a product. You really want to get quick iteration and get early feedback and then come back and refine your product thinking and product ideas.

Embrace resistance as a learning opportunity.
Katie Womersley: I got quite a bit of pushback on wanting to decrease Cycle Time. Engineers were really enjoying having work-in-progress PRs. They liked being able to say: well, here’s the shape of something, and how it could look as a technical exploration, and some of that was actually valid… But the real concern here is, we are using metrics as a way to have data-informed discussions. It’s a jumping-off point for discussion. It is not a performance tracking tool. And that seems to be the number one thing, and that’s important. We’re not trying to stack rank who has the most productive impact and then fire the bottom 30%. We’re trying to understand at a systems level where there are blockages in our pipes; we’re trying to look at engineering as a system and see how well it’s working. I think that’s very, very important to communicate. I think for software engineering in general, we have a great culture for the most part of blameless postmortems, understanding human factors in engineering, and not attributing outages solely to human error. Basically, you want to take that mindset that you already have from incident response and incident management, and you want to apply that now into team process management as well.
Bonnie Aumann: Esther Derby has a podcast called Tea And The Law Of Raspberry Jam, which actually has an entire episode on coaching past resistance, and the most important part is actually to try to take that word out of your vocabulary. Resistance almost always comes from somebody who really cares and sees value in what is happening. And if you can understand where they’re coming from, you can learn better about how you might introduce something and get a better idea of what will benefit the team and the company. And it’s not to say that you need to be held hostage by one cranky person, but that one cranky person might just have liked a little bit more information for you than you knew before.

Bryan Helmkamp: In speaking with so many engineering organizations and getting started with data and insights, I think it can feel a little bit difficult to get started. It can feel a little bit like, “We have to get this exactly right.” And it’s common that people, as with anything, will make some mistakes along the way. So my recommendations for that are, give yourself the space to start small, maybe just looking at even one tactical thing. “How long is it taking for us to get code reviews turned around?” is a great example. Really focus on building up trust through the organization because trust is a muscle. And as you exercise it, it’s going to grow. Incrementally paint the picture to the team of what you’re trying to achieve and give them the why behind it, not just the what.

Design a Code Review process that works for your team.
Katie Womersley: Something that we do – and this is really controversial – but the vast amount of PRs are merged without review. This will probably shock many people, and the reason we do that is in every asynchronous team: when you’re waiting for review, you lose context…We have a rating system for our PRs. In fact, most of them are small PRs. They’re uncontroversial changes. And we actually don’t need that developer to wait a whole day for somebody to come online to say: ‘Arms up, let’s march.’ It’s just not that risky. Also, we’re in social media management. We don’t make pacemakers. Just from a business perspective: how badly wrong can things go? Most of our PRs are absolutely safe to merge without review. And then you will get PR comments, which are aimed at individual growth and performance, saying this could have been done in a cleaner way, for example. And then on the next PR, hopefully, the engineer would incorporate that advice.
For high profile PRs (e.g., you’re changing Login, you’re changing Billing), yes, that needs to get reviewed before going out … Most people will say it’s really important to have code reviewed before you merge things. And is that nice to do? Yes, it is. But in our very asynchronous team, what is the effect of doing that? Actually, it is a negative effect. So a lot of our code does not get reviewed before merge.
Bala Pitchandi: I couldn’t agree more on the over-relying on reviews. At VTS, we do pair programming a lot. Even when two developers were paired on a PR, we used to still require a third person to review. Later, we just figured that two people working on a PR is enough of a review, so that if you’re pairing on a PR, you just merge it.
As coding days go down, productive impact scores go up.
Bala Pitchandi: I guess, of all the bad things that happened with the global pandemic, one benefit was that we all went distributed. Our Cycle Time actually went down by 20% without having to do anything. Something that you often hear about engineers is that they’re always complaining about distraction. There’s too much noise, people are talking, they want a noise-canceling headset. We were like, you know what? There is actually truth to that because when everyone went remote, guess what? There was less distraction, they had more heads-down time, and they were actually able to contribute to getting the code through the pipeline lot faster. And then we were able to build on that. Focusing on the team-level metrics and encouraging the teams to really focus on their own things that they care about was really helpful.
Bonnie Aumann: We’ve been remote from the beginning. The pandemic made everything more intense. I think is what we really learned. And the thing that became harder was making sure that people took the time and space to actually turn off and recharge. One of the anti-pattern practices is that on a team of very senior people, each person will take something to do and then push it forward. But then, of course, your overall Cycle Time on each of those goes down because you haven’t focused on pushing it all the way through. I think there’s been a lot of cultural outreach from managers to employees to be like, have you hydrated today? Have you done your basic care? When was the last time you saw the sky? It makes it more of a complete package.
Katie Womersley: I have a great mini-anecdote on that. We switched to a four-day workweek to get ahead of burnout with the pandemic. And what we saw in our data was, while the number of coding days went down; obviously, it’s a four-day workweek. We actually saw a productive impact score go up across every single team…We’re getting more done in four days than we were in five days, which is completely wild, but we can show that’s working. We’re in company planning discussions now, and we’re asking, “Should we move back to a five-day workweek to get our goals achieved?” But the data actually shows that we’ll get less done because people will be more burned out.
Agile provides teams with valuable vernacular, but be wary of doing agile by the book.
Bonnie Aumann: I think it’s complicated, but I’ll try and narrow it down. An absolute unit of agile is feedback and feedback cycles. When you’re looking at a thing like Cycle Time, it is a tool to let you know how fast you’re going, but it’s just information. What you do with that information is up to you. If you see people are working seven days a week and you think that’s a good thing, then you’re going to use it to make sure that it’s a good thing.
I will say that one of the things that is beneficial of doing agile by the book, particularly if you’re doing it by The Art of Agile Development or some of the books that really get down into the nitty-gritty, is that you have everybody speaking the same language, you have people using the same words. Because one of the hardest things about getting good metrics on a multi-team situation is making sure that people are using words the same way. And when something opens and when something closes, is when something starts and when something finishes. If you’re using Trello in one place and JIRA in another place, and GitHub issues in a third place, getting that overall view of what your data is, is challenging.
The more you rely on concrete data, the more flexible you can be.
Katie Womersley: It’s so important to look at your metrics and figure out what actually works with the team you have and the situation you’re in, and not just listen to a bunch of people on a panel and be like, “We must do that.”

Bryan Helmkamp: Your point reminded me of an interesting quote about agile and just this idea of process adherence becoming the goal in and of itself. I think the quote was something like, if you’re doing agile exactly like the book, you’re not actually doing agile. It’s inherent. To bring this around to Cycle Time and data, the answers are different for every team. But what I think is really powerful is that by having a more clear objective understanding of what’s going on, that opens the door to more experimentation. And so it can free up a team to maybe try a different process than the rest of the org for a while. Without it just being like: Well, we feel this or that, and being able to combine both of those things into a data-informed discussion afterward about how it went and being able to be more flexible despite the fact that data may make everything feel more concrete.

Continuous Delivery is the ability to ship code quickly, safely, and consistently, and it’s a necessity for teams that wish to remain innovative and competitive. It’s focused on delivering value to the user and starting that feedback loop early — the ideal state of Continuous Delivery is one in which your code is always ready to be deployed.
Many engineering leaders think of CD as a workflow and focus on the tooling and processes necessary to keep code moving from commit to deploy.
But CD is more than just a process — it’s a culture. To effectively practice CD, you need to:
- Convey the importance of CD to your team
- Create a blameless culture, one in which developers feel safe dissecting and learning from mistakes
- Facilitate alignment between business goals and CD.
With the right culture in place, your team will be better positioned to get their code into production quickly and safely, over and over again.
Explain why CD is important
Processes fail when developers don’t understand their rationale. They may follow them in a nominal way, but they’ll have a hard time making judgment calls when they don’t know the underlying principles, and they may simply bend the processes to fit their preferred way of working.
Code Climate’s VP of Engineering, Ale Paredes, recommends starting with context over process. Explain why you want to implement CD, reminding your team members that new processes are designed to remove bottlenecks, facilitate collaboration, and help your team grow. As they get code into production faster, they’ll also get feedback faster, allowing them to keep improving their skills and their code.
Then, you can set concrete, data-based goals that will allow you to track the impact of new processes. Not only will your team members understand the theoretical value of CD, meeting these new goals will help prove that it works.
Connect with individual team members
Ale warns that when an individual developer isn’t bought into the idea of CD, they’ll “try to hack the system,” doing things the way they want to, while working to superficially meet your requirements. This may seem like it accomplishes the same goal, but it’s not sustainable — it’s always counterproductive for a team member to be working against your processes, whether those processes are designed to promote CD or not.
She recommends using 1-on-1s to get a sense of what motivates someone. Then, you’ll be able to demonstrate how CD can help support their goals. Let’s say a developer is most excited about solving technical challenges. You might want to highlight that practicing CD will allow them to take end-to-end ownership of a project: they can build something, deploy it, and see if it works when they’re shipping small units of work more frequently. If another team member is motivated by customer feedback, you can remind them that they’ll be getting their work into customers’ hands even more quickly with CD.
Creating a blameless culture
Once your team is bought into the idea of Continuous Delivery, you’ll need to take things a step further. To create the conditions in which CD can thrive, you’ll need to create a blameless culture.
In a blameless culture, broken processes are identified so that they can be improved, rather than to levy consequences. It’s essential that team members feel safe flagging broken processes without worrying that they’ll be penalized for doing so or that they’re singling out a peer for punishment.
A leader can help establish that blamelessness in the way they communicate with their team members. Ale’s rules for incident postmortems clearly state that there is no blame. Names aren’t used when discussing incidents or writing incident reports because the understanding is that anyone could have made the same mistake.
Convince the C-Suite
Fostering the right culture on your team is essential to effectively implementing Continuous Delivery, but it’s not enough. CD also requires support from the top. If your company is looking for big, splashy releases every quarter, Continuous Delivery will be a tough sell. Frequent, incremental changes are almost fundamentally at odds with the roadmap that the organization will set out for engineering, and how it will measure success.
To bring Continuous Delivery to an organization like this one, you’ll benefit from applying one of the core principles of CD: incremental change. You won’t be able to drive a seismic shift in one push. Instead, you might try Ale’s strategy and look for ways to introduce small changes so you can start proving the value of CD. For example, you might try automating deployments, which should cut back on incidences of human error and free up developer bandwidth for writing new code.
The Virtuous Circle
Process may start you on your way to Continuous Delivery, but you won’t get far. Pair those processes with a culture of CD, and you just might reach the Virtuous Circle of Software Delivery — the point at which each improvement yields benefits that motivate developers to keep improving.

Engineering managers often rely on subjective clues to assess how their team is doing. But decisions made based on gut feel and imperfect measurements are less than ideal — sometimes they result in team success; other times they result in disappointment. Subjective measures need to be supplemented with objective data; with a combination of the two, managers are more likely to make choices that benefit their teams.
When baseball managers learned this lesson, it got the Hollywood treatment. Moneyball depicted the metrics-first approach to baseball management popularized by Billy Beane, former General Manager of the Oakland A’s. Employing three lessons from Beane’s management approach can help engineering leaders drive productivity and efficiency on their teams.
Lesson #1: Use objective metrics
Beane gained notoriety for prioritizing statistics over scouts’ instincts and consistency over flash. This approach is rooted in sabermetrics — the field dedicated to “the search for objective knowledge about baseball” and statistical analysis of the sport.
Though sabermetrics was founded by baseball fans, Beane applied this predilection for objectivity to managing his team. Rather than relying on scouts’ instincts, intangibles like a player’s footwork, or prestigious metrics like batting average, Beane favored a selection of under-appreciated metrics more closely correlated with consistent results.
Historically, software development has been a field lacking in objective measurements. Classic workload estimates like T-shirt sizes can be useful for internal scoping but are too subjective to translate throughout an org; one team’s size “XL” project is another team’s “Medium.”
Engineering leaders need objective measurements. Our version of sabermetrics involves analyzing the data generated by our own VCS, which is full of objective data about the number of Commits logged in a given period, or the length of time a Pull Request stays open before it’s picked up for review. Objective measurements can help engineering leaders measure progress across teams, projects, and quarters, and are instrumental in setting and achieving effective departmental goals.
Lesson #2: Focus on leading indicators
Of course, not all objective data is equally useful; one of the hallmarks of Beane’s strategy involved the careful selection of metrics. When recruiting, most managers looked at a player’s batting average — the number of times they hit a ball into fair territory and successfully reached first base, divided by their number of at-bats. Beane looked at their on-base percentage, or OBP, a measure of how often a batter reaches first base, even if they get there without actually hitting the ball.
A player must be a good hitter to have a good batting average, but what puts them in a position to score a run is getting to first base. From a data-first perspective, the value of an at-bat is not in the hit itself but in the player’s two feet making it safely to first.
Similarly, to the rest of the organization, your team may be defined by their most eye-catching stats and praised when they deploy a much-anticipated revenue-generating feature. But just as a player’s batting average doesn’t account for every time they get on base, a list of features completed can only reveal so much about your team’s productivity.
The true measure of your team’s success will be their ability to deliver value in a predictable, reliable manner. To track that, you’ll need to look past success metrics and dig into health metrics, measurements that can help you assess your team’s progress earlier in the process.
For example, an engineering manager might look at “Time to Open,” which is a measure of the period between when a developer first logs a Commit in a Pull Request and when that Pull Request is finally opened. Code can’t move through your development pipeline until a Pull Request is opened, and smaller Pull Requests will move through your pipeline more quickly.
Time to Open is similar to OBP. It’s not a prestigious metric, but it’s a critical one. Just as you can’t score if you don’t get on base, your team can’t deploy code that never makes it to a Pull Request. As a manager, you need to make sure that developers are opening small, frequent Pull Requests. If they’re not, it may be worth reinforcing good code hygiene practices across your team and speaking directly with developers to determine whether there’s something particular that’s tripping them up in the codebase.
Lesson #3: Use Metrics in Context
Of course, Beane’s approach wasn’t perfect. Metrics alone can’t tell you everything you need to know about a potential player, nor do they hold all of the answers when it comes to engineering. Data is useful, but leaning too strongly on one metric is shortsighted.
Though Beane was famous for seeing the value in a player’s OBP, there’s also evidence that at times, he relied too heavily on that one metric. Not every college player with a strong OBP was cut out to play professional baseball. While a scout might be able to differentiate between a promising young athlete and one who was unlikely to succeed, a metric can’t make that distinction.
As an engineering leader, you need to rely on a combination of instinct and data. Start with how you feel — is your engineering team moving slow? — and then use metrics to confirm or challenge your assumptions. When something is surprising, consider it a signal that you need to investigate further. You might need to re-evaluate a broken process or find new ways to communicate within your team.
Beane’s approach to managing his team was headline-grabbing because it was revolutionary, representing a major shift in the way fans, commentators, and managers thought about the sport of baseball. Many of his groundbreaking strategies are now commonplace, having been adopted across the league.
Data-informed engineering leadership is still at that revolutionary stage. It’s not standard practice to use objective engineering metrics to assess your team’s progress or guide its strategy, but it will be.

One critical engineering metric can help you innovate faster, outrun your competition, and retain top talent: Cycle Time. It’s your team’s speedometer, and it’s the key to everything from developer satisfaction to predictable sprints. And Cycle Time has implications beyond engineering — it’s also an important indicator of business success.
That’s why we’re excited to announce the release of our new book, The Engineering Leader’s Guide to Cycle Time. For those looking to boost their team’s efficiency and productivity, we offer a data-driven approach, backed by research, case studies, and our own experience as an industry-leading Engineering Intelligence platform.

The book dives into the components of this critical metric, breaking down the development pipeline into distinct stages to highlight common bottlenecks and opportunities for acceleration. The foreword, by Edith Harbaugh, CEO and Co-Founder of LaunchDarkly, places Cycle Time in context, explaining how it’s integral to the latest shift in software development methodology — the shift towards CI/CD.
Download it now (it’s free!) for a breakdown of the most important engineering metrics, strategic advice on increasing engineering speed, and real-world advice from senior engineering leaders.


As part of this year’s Engineering Leadership Summit: Virtual Edition, we spoke to Edith Harbaugh, CEO and Co-Founder of LaunchDarkly. She discussed Progressive Delivery and the importance of Cycle Time. Below is an excerpt from the fireside chat portion of Edith’s session, edited for length and clarity.
Hillary Nussbaum, Content Marketing Manager, Code Climate: Welcome to the closing session of this year’s Engineering Leadership Summit, featuring a conversation with Edith Harbaugh, CEO and Co-Founder of LaunchDarkly. Edith and I will be talking about continuous delivery, specifically talking a little bit about what she wrote in the foreword of our upcoming book, The Engineering Leader’s Guide to Cycle Time. Let’s jump right in. Edith, do you mind introducing yourself? Tell us a little bit about what you do and how you got to where you are today.
Edith Harbaugh, CEO and Co-Founder of LaunchDarkly: Hey, I’m Edith Harbaugh, I’m CEO and Co-Founder of LaunchDarkly, a feature management platform. We have customers all over the world, like Atlassian, BMW, who rely on us to get the right features to the right customer at the right time. And we do this at massive scale — we serve trillions, trillions with a T, of features every day.
That’s great. Tell me a little bit about what software development and delivery were like when you first started, and how things got to where they are today, and then where LaunchDarkly fits into all that.
So I started back in the ’90s, and I always loved software because it was a way to bring stuff to life, it was a way to create something from scratch and get it out to the world. The way software was built back in the ’90s was very different than it is now, and that was because you had to physically ship software. So you would have a team of engineers at Microsoft, for example, who would work for three years, and they would release it to manufacturing and print all the bits on a bunch of disks, and then ship them out. And you would actually go to the store and you would buy a box of software, and then you would sit at your computer and you would feed all those disks into your computer, and that would create Microsoft Excel or Microsoft Word. This was pretty cool because then you could use Microsoft Excel, which I still love.
It also created a lot of habits around software — when it went to manufacturing, it had to be perfect. Somebody’s going to buy a 25-disk box of Microsoft Word and then install it on their computer, and it better be good because they’re not going to do that every day. They might not even update it every year. You might have service packs where somebody would go and get an update, but most people are fine if it works okay.
Microsoft had a very small bug in Excel where if you did some esoteric computation, they were off by some fraction, and that was actually a huge deal. So because software was so hard to get, there was a lot of pressure all through the release train to make it perfect. This has to be right, we only get one chance. We only get one chance to get this out to our customers and this has to be absolutely right, we don’t get a second chance.
How exactly do you feel that impacted things moving forward? Even as people started to change their delivery model, do you still see holdovers from that today?

The massive sweeping change that happened — and it’s still happening, to be honest — is from packaged software to software as a service in the cloud. I’m looking at my computer right now, it doesn’t even have a slot for disks, it just doesn’t work that way anymore. You get your software from the cloud, virtually. And what this has really changed is that it’s okay to move a little bit faster, because you can change it. The whole idea that we’re going to have Windows 3.7 Service Pack 6 is just gone now, now you can get a release whenever you want.
And how that’s changed software is it’s really freeing and liberating in a weird sort of way. Think of the poor engineers of the ’90s, when you only had a three year window to work and then ship. It got very political, it got very hard, because you’re like, “I have to make a guess about what people will want three years from now. If I’m wrong, I won’t have a chance to fix it.” So there’s just a lot of polishing and then an inability to adjust on the fly. If you were a year and a half into your release cycle and you realized you were completely wrong, it was just really hard to scrap that. So the biggest change has been with Agile and software in the cloud, that you have a lot more freedom. You could do a week long sprint and say, “Hey, let’s get this out to market. Let’s test this, let’s do this.”
And where do Continuous Delivery and Progressive Delivery fit into all that? Agile is a step past waterfall, but I would say that Continuous Delivery takes that even a step further. How do you see that all fitting together?
So Continuous Delivery was a step past agile in that it was this idea that instead of doing a release every year or every six months, that you could just release whenever you wanted. Jez Humble and David Farley really popularized this theory with a book called Continuous Delivery, where it’s like, okay, let’s make it so you can release any time you want. This was extremely popular and extremely scary at the same time. With big sites like Facebook, it just gave them this extreme competitive advantage. If you can ship 10 times an hour, or 50 times an hour, or 100 times an hour, and your competitors are shipping once a quarter, of course you’re going to have better software. You can fine tune things, you can dial them in, you can get them right. The downside to Continuous Delivery, and why we came up with Progressive Delivery, is that it’s terrifying. What I just said about how you can ship 10 times, 50 times an hour — if you’re a big bank or an insurance company, that’s absolutely horrifying. I’ve got customers who are depending on me, and I don’t want that. Or if you’re an airline, for example, you have regulations, you’ve got people in the field, you cannot have people just check in 50 times an hour and cross your fingers and hope that everything works out.
Even Facebook has moved away. Their mantra used to be, “move fast and break things,” now it’s “move fast with stable infrastructure.” How they got there was Progressive Delivery, which is basically having a framework which decouples the deploy, which is pushing out code, from the release, which is who actually gets it. And with Progressive Delivery, what you have is you have the ability to say, “Okay, I have this new amazing feature for looking at your bank balance, which makes it much clearer where the money is going.” And instead of pushing it out to everybody and crossing your fingers and being like, “Please let people not have negative balances,” let me deploy this code safely, and then turn it on, maybe, for my own internal QA team, my own internal performance testing team, and make sure I’m not overloading my systems, and let me roll this out maybe just for people in Michigan, because they might also have Canadian currency, because they’re so close to Canada. Let me just do some very methodical and thoughtful releases. So you get all the benefits of Continuous Delivery, but you have this progression of features.
What are the benefits to those more frequent releases? Obviously, as you’ve said, you can move more quickly, you don’t have a three year lag on what people want, but what are the other advantages?
You can move more quickly forward, you could also move more quickly back. Because if, from the very beginning, you say, “I am going to think carefully about how to segment this feature so that I can release it discreetly to some people,” that also means that you can roll it back very easily. So the way we used to build code was you used to have this massive, huge, monolithic code and you pushed it out, and then if something broke, you couldn’t fix it. You just had to take the entire release back, which was very, very painful. But if you say, “Okay, I have this new feature for bank balances and I’m just going to push this out alone, and if it’s not working and buggy, I can just turn it off.” That’s really awesome, that gives you, as a developer, a lot of stress relief.
Yeah. And to look at it again from the developer perspective, how can you empower developers to move quickly and to implement Continuous Delivery practices so it’s not just top down, someone telling everyone to move faster, but developers actually being in control and having the ability to move quickly?
I think it’s a restructuring of breaking down units of work into smaller and smaller and smaller units. If I want to move quickly, I need to break down this release that used to take six months into the smallest unit that I can do in a week? And then here’s a bitter secret I learned the hard way, some features don’t need to get built. Some features, if you get two weeks into it and you put it out to the world, and the world says, “You know, we don’t really care about that at all,” it’s much easier just to say, “Hey, we had these bright hopes for this feature, but we don’t need to release it. And if this was a six month project, we can save five and a half months of work.”
Making a small increment of progress and figuring out, “Hey, you know what? We really thought everybody wanted this, but they don’t.” Or, “Hey, we have this six month plan, and once we started going this way, we figured out that we really need to go a little more that way.” And if you are doing a whole six month release, you’re just basically drawing a line. If you’re doing it in two week sprints, you could be like, “Hmm,” and end up where you really want to be. Or even just say, “Hey, you know what? We don’t need to do this. This was a bad idea.” And it’s a lot easier, politically, to realize that two weeks in, than six months in.
Absolutely. It seems like you’d give the team a little bit more control over direction as well. And so given that a lot of teams have gone remote now, either permanently or temporarily — does the importance of Continuous Delivery change at all on a fully remote team? And then, are there particular considerations, is it harder, easier, how does it look?

Continuous and Progressive Delivery are even more important than ever. A lot of the things that you could do when you’re all in the same office, you just can’t do anymore. You can’t just yell out, “Hey, is everybody ready to ship right now?” You could try to do that on a Slack, but people might be getting coffee or taking care of a kid. So you have to have even more controls about what is happening when, what is being shipped out, and who has rights to see that. And you also may need to be able to react very quickly. I keep coming back to financial customers, because in the last six months, they have had, I think, 30 years of progress crushed into six months, in terms of people not being able to go into banks anymore. Suddenly everyone wants to check their balance at home, wire money at home, or transfer money. Before the answer was kind of, “Just go to your branch.” You don’t have that anymore, you have to be online. It’s not a choice, it’s not an either-or anymore. You absolutely have to have online support for a lot of functions.
The same thing is happening, sadly, to a lot of functions all over the world, where it used to be like, “Just get to your office fax machine.” You have to have a truly digital function for everything right now.
Yeah, it’s interesting. So it’s a change, not just for the developers, but a change for the end user, and it’s even more important that this innovation is happening, and it’s happening quickly.
Yeah. It’s happening extremely quickly. A lot of processes used to be half digital, half paper and now, you have to be fully digital.
Do you have any tips for teams that are working to coordinate while they’re distributed and working to implement Progressive Delivery?
Take it in small steps. I talked in the beginning about Microsoft transforming from a three year release to releasing every week or so, and I also said you need to do this very quickly, but you also need to do it right. So get comfortable with some low-risk features first. Don’t say, “Hey, we’re going to move from a three-month cycle to a daily cycle,” that’s terrifying. But if you’re at a three-month cycle, look at, “Hey, are there some low risk features that we could try to do in a week-long sprint? Is there something that we can carefully detach and figure out a basic rhythm before we get more into this? Let’s figure out the issues that we have, whether they be communication, tools, or process, on something where if it fails, of course failure’s never awesome, but it’s not hugely not awesome.”
I mentioned that you wrote the foreword to the Engineering Leader’s Guide to Cycle Time. Where does Cycle Time fit into all this? Why is it important when you’re trying to move to Continuous or Progressive Delivery?
Cycle Time is so important. The smaller the batches of work you do, the more impact each batch can have. If everything takes six months, you just don’t have many opportunities, you just don’t have many at bats. If you break it down so that you can say, “Okay, let’s try something new every month,” even that alone is a 6X improvement every month. If you break it down further, you just get more and more chances.

And the really seductive part of Continuous Delivery for a developer is that it’s really fun to see your stuff out in the world. If you’re an engineer, like I was in the ’90s, and you’re grinding away for months on a project, you don’t really get much of a feedback loop. You get your manager saying, “Hey, keep working,” but you don’t get any real validation from the customer. So if you can break down your Cycle Time so that you can say, “Every week, this is out in the hands of our customer, and they tweeted that they loved it, or they put in a support ticket that they had some issues but they liked it and wanted to work with us,” that’s really, really fun for a developer.
The worst thing for a developer is, number one, the worst thing is you ship something and it just totally breaks. The second worst is you work really hard on something and then nobody cares, and you’re like, “Well, I gave up seeing my kid’s practice, or I gave up this happy hour with a friend because I was trying to get this done, and nobody cares.” Which is just hard. So if you’re in this shorter Cycle Time as a developer, where you’re like, “Okay, we worked hard this week and we got it into the hands of the customer, and here’s the five tickets they already opened about how to improve it,” that actually feels really good. It feels like I am helping somebody.

“Our analysis is clear: in today’s fast-moving and competitive world, the best thing you can do for your products, your company, and your people is institute a culture of experimentation and learning, and invest in the technical and management capabilities that enable it.” – Nicole Forsgren, Jez Humble, and Gene Kim, Accelerate.
After finishing the Accelerate book, many engineering leaders are determined to build a high-performance team. Readers go to the ends of the internet looking for the right tools and processes to facilitate speed and stability.
Lucky for us, to summarize every area that can be improved and move the needle, the authors put together this simple flowchart:
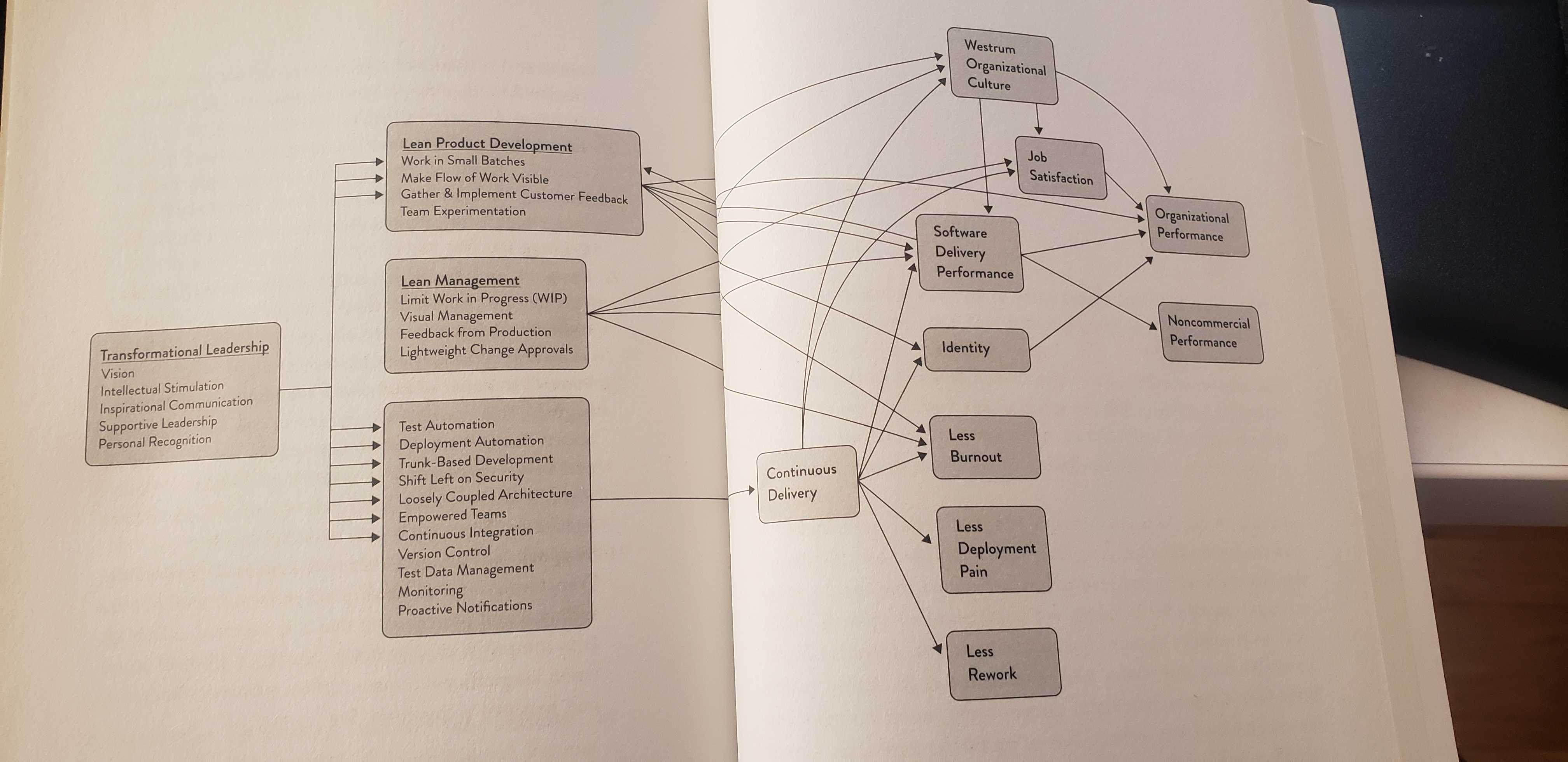
Just kidding. It’s not simple at all.
The tl;dr of the chart above is that changes to behaviors, processes, and culture influence several outcomes, such as burnout, deployment pain, or overall organizational performance. So while the book gives you a comprehensive explanation of everything that can be done, it doesn’t answer the most important question: if I want to improve how my team works, where do I start?
Metrics != Strategy
Ever since we built a Software Engineering Intelligence (SEI) platform, many engineering leaders have come to us and asked: “What metrics should I track?” And more recently: “How do I track Accelerate metrics within the platform?”
The Accelerate metrics, specifically, are valuable in giving engineering executives an understanding of where their organization stands, compared to the rest of the industry. They’re not:
- Specific to the problem you’re trying to solve.
- Diagnostic to indicate when you should take action.
While engineering teams can track Accelerate metrics in their custom-designed SEI platform, powered by Code Climate (along with 40+ other metrics), we always advise leaders to first take a step back and consider what they’re trying to improve. Quantitative measures are a powerful tool to measure progress toward objectives—but these objectives can vary drastically between organizations or even between teams. Measuring metrics with no end goal in mind can lead to poor decision-making and a focus on the wrong priorities.
Instead, we recommend starting by determining your team’s objectives and then pairing them with the appropriate metrics. Then you can use metrics as a means to an end: measuring progress toward a clear direction. This will ensure your metrics are more actionable in the short term and will be received more favorably by the team.
Specific: Start with the Pain
We always recommend that engineering leaders begin with qualitative research. Prioritize conversations before looking at quantitative measures to work through the most immediate and painful issues.
Through stand-ups, retrospectives, and 1:1s, work to understand what feels broken to the engineers. To avoid exposure or recency bias, collaborate with peers in management or lead engineers to gather this data to find repeat points of friction.
Based on your team’s observations, record your hypothesis:
Our code review process is often painful. I’ve heard that some reviewers “always approve PRs,” and often overlook defects. Other team members complain that specific individuals consistently ask for multiple rounds of changes, regardless of the magnitude of the change.
Try to include concrete details to make sure you’ve completely and accurately captured your team’s shared sentiment. Once you’ve worked to understand the day-to-day friction, only then should you begin to look at quantitative measures. The example above might call for the following metrics:
- Code Review Speed: How quickly do reviewers pick up PRs?
- Time to Merge: Once a PR is opened, how long does it take to merge?
- Review Cycles: How many times, on average, does a PR go back and forth between its author and reviewer?
- Code Review Involvement: How is Code Review distributed among Reviewers?
- Code Review Influence: How often do reviews lead to a change in the code or a response? (e.g., How valuable are these reviews?)
Look at these metrics historically to see whether they’ve been increasing or decreasing. You can also look at them in tandem with overall Cycle Time (time between the earliest commit and when a PR is merged to master) to see which have the biggest impact on the team’s speed.
Diagnostic: Distinguish Drivers from Outcomes
A common mistake leaders make when first implementing metrics is looking at outcome metrics and then making assumptions about their Drivers. Often, however, an output metric, such as Cycle Time, is spiking due to an upstream issue. Unclear technical direction, big batch sizes, or a single nit-picky reviewer can all contribute to a high Cycle Time.
Drivers are typically leading indicators. They’re the first quantitative sign that something is going the right direction, and they will, in turn, affect your outcome metrics, which are your lagging indicators. Your leading indicator is representative of an activity or behavior, whereas your lagging indicator is usually a count or a speed, which is the result of that behavior.
In the example we’re using for the piece, here’s how you would split up your metrics:
- Leading Indicator (Driver): Review Cycles, Code Review Involvement, Code Review Influence
- Lagging Indicator (Outcome): Time to Merge
While you diagnose your issue, you’ll want to look at both the Drivers and Outcomes.
Over time, you may discern certain patterns. You might notice that as Code Review Involvement goes up, Code Review Influence goes down. From those data points, you may want to investigate whether overburdening a reviewer leads to undesirable results. Alternatively, you might want to look into teams whose Review Cycles are much higher than others’ (with seemingly no difference in outcome).
Once your team has improved, you can step back from looking at Drivers. Outcomes for your team will serve as at-a-glance indicators for whenever a team or individual is stuck and may warrant your support as a manager.
The Path to High-Performance
The research found in Accelerate suggests that quantitative measures are important—but it also argues that the most successful leaders take a thoughtful and deliberate approach to improving how their organizations work:
“Remember: you can’t buy or copy high performance. You will need to develop your own capabilities as you pursue a path that fits your particular context and goals. Doing so will take sustained effort, investment, focus, time. However, our research is unequivocal. The results are worth it.” – Nicole Forsgren, Jez Humble, and Gene Kim, Accelerate.

This post is the fifth and final article in our Tactical Guide to a Shorter Cycle Time five-part series. Read the previous post here.
If developers’ change sets aren’t always deploy-ready upon merging, your team is not practicing Continuous Delivery.
The final step to fully optimizing your time to market (or your Cycle Time) is to indoctrinate seamless deployment, holding every engineer responsible for keeping the main production branch in a releasable state.
Impediments to true Continuous Delivery fall into three categories:
- Process: Your process involves many manual blockers, including QA and manual deployment.
- Behavioral: Your managers or engineers lack confidence. They’re not sure whether defects will be caught before merging or whether their team can respond to issues uncovered after deployment.
- Technical: Your current tooling is either lacking, too slow, or breaks frequently.
This post will walk you through mitigating each obstacle so that you can achieve a deploy-ready culture on your engineering team.
Work through Process Impediments
Transitioning to a CD process requires every person on your development team to spend their time as strategically as possible. This ruthless approach to time management requires automating everything you can in the deployment process— particularly, any manual phases that completely block deployment.
On many teams, the hardest transition is moving away from a process in which humans gate shipping, such as manual QA and security checks. These stamps of approval exist to give your team confidence that they’re not shipping anything that isn’t up to snuff. To eliminate these blockers, you’ll need to address quality concerns throughout your software dev process—not just at the end.
Remove QA as a Blocker to Deployment
The purpose of testing, whether manual or automatic, is to ensure software quality is up to standard. Many of the practices within CD, such as working in small batches and conducting Code Review, inherently serve as quality control measures. Any major defects that your team doesn’t catch during development should be caught with automated testing.
To reduce the risk associated with removing QA as a blocker:
- Automate testing throughout the software development process (not just at the end). Where and what you test will depend on a multitude of factors, but consider testing as early as possible to ensure developers can make changes before putting in too much work.
- Do not overtest. Overtesting may lead to long build times and will simply replace a manual bottleneck with an automated one. We recommend trying to ensure that test coverage is sufficient enough. If an issue isn’t caught and does break in the middle of the night, it doesn’t require waking up an engineer.
- Use feature flags and dark launches. If there are deployment risks that you have not yet mitigated, use feature flags to roll out changes either internally or to a small sample of your customer base. For further research, check out Launch Darkly’s full e-book on Effective Feature Management.
Once you have these components in place, you’ll want to make sure you have an effective monitoring system, where your tools surface issues as quickly as possible. Measuring Mean Time to Discovery (MTTD) alongside Mean Time to Recovery (MTTR) will help you consistently track and improve the efficiency of both, your monitoring and your pre-deploy testing suite.
Shift Security & Compliance Checks left
Security is one of the most important checks before deployment, which is why you shouldn’t leave it open to human error. Enable your security experts to think strategically about what kind of testing they should run, while leaving much of the tactical security work to the machines.
To integrate security throughout your software delivery process, consider:
- Involving security experts into the software planning and design process. Whenever a feature that handles particularly sensitive data is coming down the Continuous Delivery pipeline, include your security team in the planning and design process. This way, security considerations are baked into the process and front-of-mind for the team as they build out the feature.
- Automated source code scanning (SAST): With 80% of attacks aimed at the application layer, SAST remains one of the best ways to keep your application secure. Automated SAST tools detect all of the most threatening application risks, such as broken authentication, sensitive data expose, and misconfiguration.
- Automated dynamic testing (DAST): Frequently called black-box testing, these tests try to penetrate the application from the outside, the way an attacker would. Any DAST tool would uncover two of the most common risks— SQL injection (SQLi) and cross-site scripting (XSS).
- Automated testing for dependence on a commonly-known vulnerability (CVE): The CVE is a dictionary maintained by the Cybersecurity and Infrastructure Security Agency that you can use as a reference to make sure your automated testing has covered enough ground.
- Building secure and reusable infrastructure for the team. With the above covered, your security team can apply their expertise to create tools for the rest of the team in the form of modules or primitives. This way, they’ll enable developers without security training to write systems that are secure by default.
Naturally, there will always be manual work for your security team, such as penetration testing. If you’re folding security into your development process, however, it won’t become a bottleneck at the very end of the process, stopping features from getting out to customers.
Work through Behavioral Impediments
A survey conducted by DevOps Group found that organizational culture is the most significant barrier to CD implementation.
The behavioral change required to foster a culture of Continuous Delivery is the most difficult, yet the least discussed, aspect of adapting true CD practices. Your team needs to have confidence that their testing infrastructure and ability to respond to changes are strong enough to support Continuous Deployment.
To instill this certainty, you’ll need to create alignment around CD benefits and encourage best practices throughout the software delivery process.
Create Organizational Alignment on Continuous Delivery
If properly communicated, the Continuous Delivery pipeline should not be a hard sell to engineers. CD unblocks developers to do what they like most—building useful software and getting it out into the world.
Three intended outcomes will help you get both managers and engineers invested in Continuous Delivery:
- Less risk. If the testing infrastructure is solid (more on this below), and the developers agree that it’s solid, they will feel more comfortable shipping their changes upon merging.
- Higher impact for the individual developer. When developers have the power to merge to production, they feel more ownership over their work. Due to sheer expectations of speed, the Continuous Delivery pipeline minimizes top-down planning and gives developers the ability to make more choices related to implementation.
- Less blame. Because ownership over a feature isn’t siloed in one individual, the software development process becomes much more collaborative. Distributed ownership over features eliminates some of the anxiety (and potential blame) when developers decide to ship their changes to production.
Equip Your Team for Change with Best Practices
Thus far, our Tactical Guide to a Shorter Cycle Time five-part series has included dozens of best practices that you can share with your team. In addition to these phase-specific optimizations, you’ll also want to coach these general principles:
- Work in small, discrete changes. When developers are scoping a Pull Request, they should be thinking: what is the smallest valuable step I can make towards this feature? When they’ve scoped and built that Pull Request, it should be deployed to production. They should avoid long-running feature branches.
- Always prioritize work closest to completion. Have developers minimize work in progress as much as possible. If you’re using a Kanban board, this means prioritizing items that are closest to done.
Don’t be surprised if this transition process takes over six months. The confidence required from your team will take a long time to build as they become accustomed to this new work style. If you’d like to move quickly, adopt CD with a team of early adopters who are already interested and motivated to make a positive change. You can learn from adoption friction in a small environment to better ease the larger organization transition.
Work through Technical Impediments
Your team can’t overcome either behavioral nor process impediments unless they have confidence in their suite of CI/CD tools. Builds that perform automated testing and deployment should be fast and reliable, while your monitoring set up gives you clear and instant visibility into how things are running.
Sharpen Your Tools
You’re not able to ship features to customers multiple times a day, if either:
- Your build is flakey, or
- Your build is slow.
And even if your tests pass, your team won’t have the confidence to set up automatic deployment, if:
- Your monitoring isn’t thorough, or
- Your monitoring isn’t well-tuned.
Again, a safe way to test the waters is to use dark launches or feature flags. Your team will be able to test how quickly issues are caught and how quickly they can recover—all without compromising the customer experience.
As you work to improve your testing builds and monitoring, we recommend slowly transitioning your manual deploy schedule to a more frequent cadence. Start with weekly deploys, then daily, then multiple deploys a day. Finally, automate the deployment process once pressing the deploy button feels like a waste of time.
The Holy Grail of Software Delivery
Every article in our series has guided you through optimizing each phase in the software delivery process. If you’ve been successful with this, then your developers are making small incremental changes, pushing frequently, and moving work through the Continuous Delivery pipeline with little to no friction.
But unless you’re actually shipping those changes to production, you’re not practicing Continuous Delivery. The point of CD (and Agile before that) was to shorten the feedback loop between customers and engineers. Working incrementally, but still shipping massive releases, does not accomplish this objective.
Deliver continuously to mitigate risk, respond quickly, and get the best version of your software into the hands of customers as quickly as possible.
Check out the other articles in our Tactical Guide to a Shorter Cycle Time five-part series:

This post is the fourth article in our Tactical Guide to a Shorter Cycle Time five-part series. Read the previous post here.
As the engineering industry has moved towards Continuous Delivery, teams have left behind many of the manual quality control measures that once slowed down delivery. Along this same vein, some engineering leaders are doubting whether Code Review still has value:
The annual survey conducted by Coding Bear revealed that 65% of teams are dissatisfied with their Code Review process– yet teams consistently identify Code Review as the best way to ensure code quality. Most people agree Code Review is important, but few know how to prevent it from wasting valuable engineering time.
Before giving up on Code Reviews altogether, we recommend looking at Code Review metrics to identify where you can avoid waste and increase the efficiency of this process.
Defining “Successful” Code Reviews
An effective Code Review process starts with alignment on its objective.
A study at Microsoft a few years ago surveyed over 900 managers and developers to understand the motivation behind Code Reviews. “Finding defects” was the primary motivator of the majority of those surveyed, but when the results were analyzed, the researchers discovered that the outcomes didn’t match the motivations. Improvements to the code were a much more common result of the reviews.
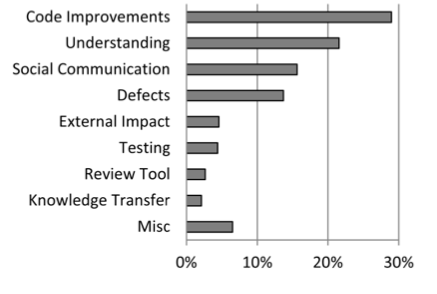
Work with team leaders to determine which outcomes you’re optimizing for:
- Catching bugs and defects
- Improving the maintainability of the codebase
- Keeping consistency of code style
- Knowledge sharing throughout the team
Determining your Code Review priorities helps your team focus on what kind of feedback to leave or look for. Reviews that are intended to familiarize the reviewer with a particular portion of the codebase will look different from reviews that are guiding a new team member towards better overall coding practices.
Once you know what an effective Code Review means for your team, you can start adjusting your Code Review activities to achieve those goals.
Code Review Diagnostics
Historically, there has been no industry standard for Code Review metrics. After speaking with and analyzing work patterns of thousands of engineering teams, we identified the following indicators:
- Review Coverage: the percentage of files changed that elicited at least one comment from the reviewer.
- Review Influence: the percentage of comments that led to some form of action, either in the form of a change to the code or of a reply.
- Review Cycles: the number of back-and-forths between reviewer and submitter.
These metrics were designed to give a balanced representation of the Code Review process, showing thoroughness, effectiveness, and speed. While imperfect (as all metrics are), they provide concrete measures that help you understand the differences between teams and individuals.
Diving into outliers will enable you to finally bring a quality and efficiency standard to Code Reviews across your organization.
Review Coverage
Review Coverage indicates how much attention is spent on reviews and represents review thoroughness. If you’ve identified that the purpose of Code Reviews is to catch defects or improve maintainability, this metric, together with Review Influence, will be a key indicator of how effective this process is.
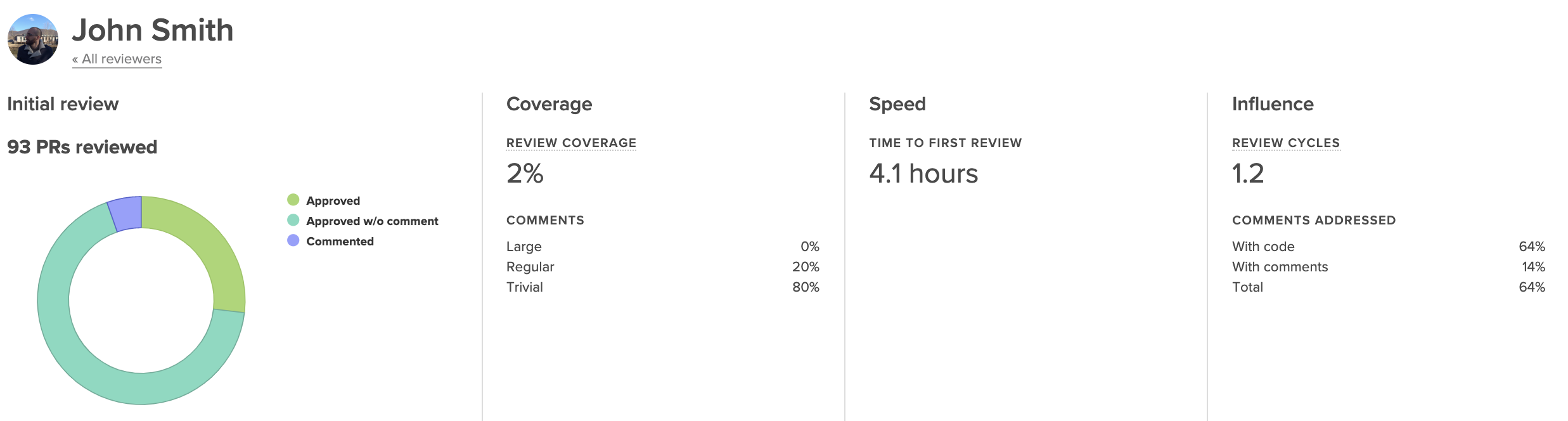
Low Review Coverage can point you toward incidents of under-review or rubber-stamping. Under-review may be happening as a result of a lack of familiarity with the codebase, disengagement on the part of the reviewer, or poor review distribution.
Unusually high Review Coverage could be an indicator of a nitpicker who’s leading to inefficiency and frustration on the team. This case will likely require realignment on what “good” is.
Review Influence
Any action that is taken as a result of a review comment is proof that the reviewer is taken seriously and their feedback is being considered. When this metric dips low, feedback isn’t resulting in change, indicating that reviews are not perceived to be valuable.
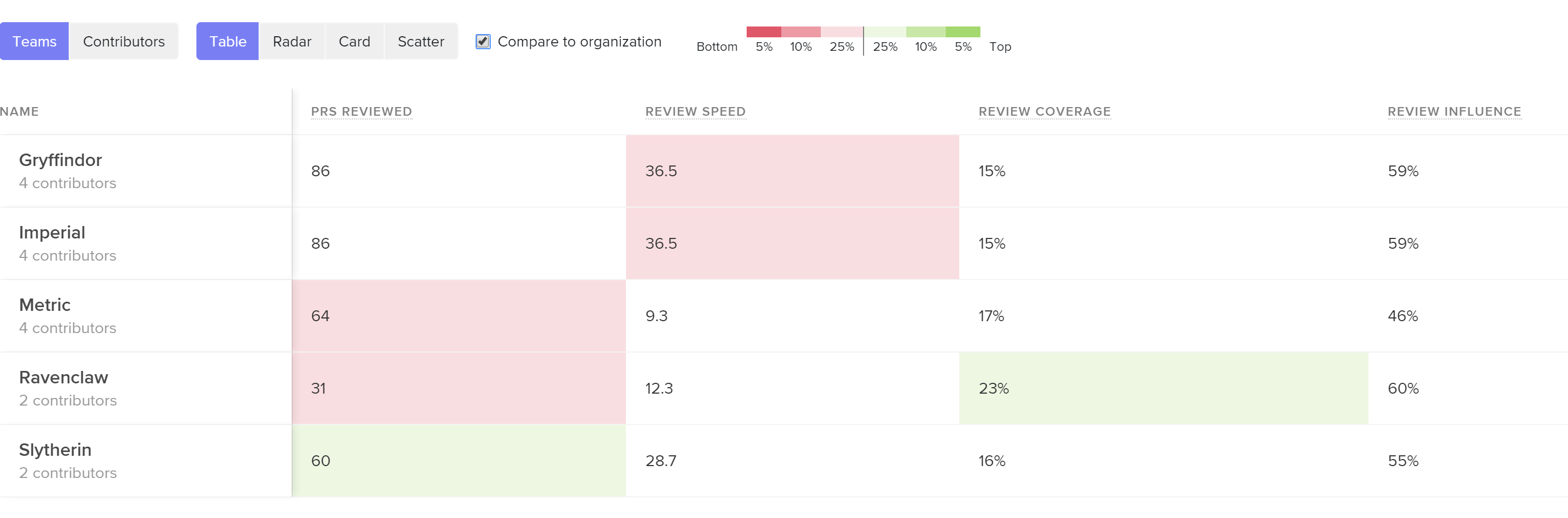
See core Code Review metrics and how they compare across teams or individuals so you can pinpoint the problem.
If you consider this metric in tandem with Review Coverage, you may identify cases where individuals or teams leave many comments (have high thoroughness) but those comments yield no action (are low impact). This can signal that there needs to be a re-alignment on the function or purpose of Code Review.
When the Review Influence is low, you’ll want to dive into the reviews that are being left on each Pull Request. When feedback that was intended to be actioned is ignored, it may indicate that the comments were unclear or the suggestion was controversial.
Review Cycles
Each time a Pull Request is passed back and forth, developers are required to context switch and spend more time on one particular line of work.
If this happens frequently, the review process can become a bottleneck to shipment and directly increase your team’s Cycle Time. Even worse, it can serve as a source of demotivation to engineers and contribute to burnout.
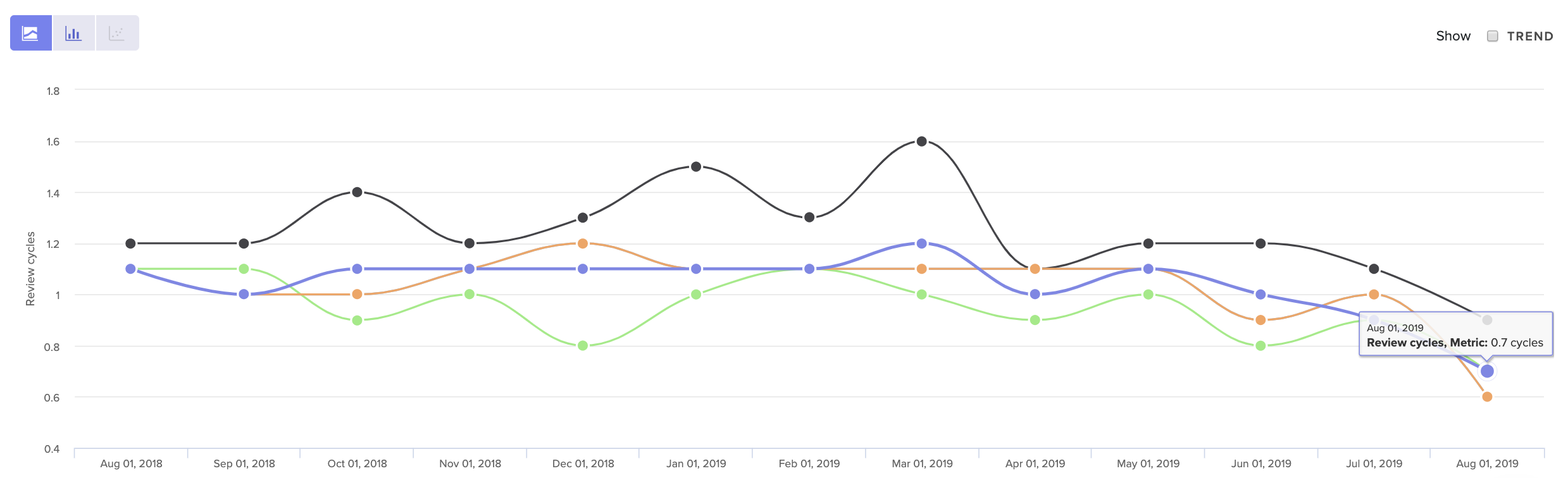
See core Code Review metrics over time, so you can get a sense of what’s normal for your team.
Look at your Review Cycle count over time to get a sense of what is typical for your team. Note that a high number of Review Cycles is typical for less experienced team members who are still becoming familiar with your codebase. Otherwise, when Review Cycles spikes, it typically represents some form of misalignment.
The source of that misalignment could be upstream, due to unclear technical direction. It may indicate that there’s a disagreement about how a solution should best be implemented. Or, more simply, team members may not have clarity about what “done” means.
Bring this data into your retros or 1:1s to start the conversation about where this misalignment may have taken place.
When to Revisit Code Review
Of all the components that influence Cycle Time, Code Review is the most difficult to get right. It requires taking a hard look at metrics, but also frequently requires difficult conversations about how to leave constructive yet respectful feedback. Often, the culture of one team is not conducive to processes have worked well for another.
For this reason, we recommend revisiting your Code Review process after any significant change to processes or team structure. This will get easier after you’ve done it once since you’ll have a clear sense of your expectations and the tools with which to communicate them.
To learn where your team should focus next, check out the other articles in our Tactical Guide to a Shorter Cycle Time five-part series:

Last Thursday, DORA released their 6th annual State of DevOps report, identifying this year’s trends within engineering departments across industries.
The good news: a much higher percentage of software organizations are adopting practices that yield safer and faster software delivery. 25% of the industry is performing at the “elite” level, deploying every day, keeping their time to restore service under one hour, and achieving under 15% change failure rate.
The bad: the disparity between high performers and low performers is still vast. High performers are shipping 106x faster, 208x more frequently, recovering 2,604x faster, and achieving a change failure rate that’s 7x lower.

Accelerate: State of DevOps 2019
This is the first of the State of DevOps reports to mention the performance of a specific industry. Engineering organizations that worked within retail consistently ranked among the elite performers.
The analysis attributes this pattern to the death of brick-and-mortar and the steep competition the retail industry faced online. Most importantly, the authors believe that this discovery forecasts an ominous future for low performers, as their respective industries grow more saturated. They warned engineering organizations to “Excel or Die.”
There are No Trade-Offs
Most engineering leaders still believe that a team has to compromise quality if they optimize for pace, and vice versa– but the DevOps data suggests the inverse. The authors assert that “for six years in a row, [their] research has consistently shown that speed and stability are outcomes that enable each other.”
This is in line with Continuous Delivery principles, which prescribe both technical and cultural practices that set in motion a virtuous circle of software delivery. Practices like keeping batch size small, automating repetitive tasks, investing in quick issue detection, all perpetuate both speed and quality while instilling a culture of continuous improvement on the team.
Thus for most engineering organizations, transitioning to some form of Continuous Delivery practices shouldn’t be a question of if or even when. Rather, it should be a question of where to start.
The Path Forward: Optimize for DORA’s Four Key Metrics
The DORA analysts revealed that rapid tempo and high stability are strongly linked. They identified that high-performing teams achieve both by tracking and improving on the following four key metrics.
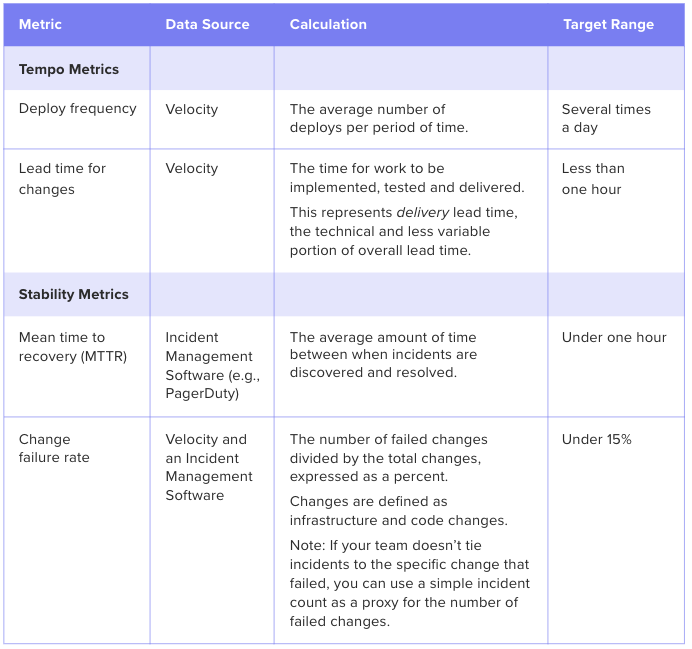
Software Engineering Intelligence (SEI) solutions provide out-of-the-box visibility into key metrics like Deploy Frequency and Lead Time. The analytics tool also reveals underlying drivers, so engineering leaders understand what actions to take to drive these metrics down.